Contents of this page is copied directly from AWS blog sites to make it Kindle friendly. Some styles & sections from these pages are removed to render this properly in 'Article Mode' of Kindle e-Reader browser. All the contents of this page is property of AWS.
Page 1|Page 2|Page 3|Page 4
Assuring Quality in Mainframe Modernization to AWS by Leveraging Atos SyntBots
=======================
By Indumathi Balaji, Sr. Consultant – Atos
By Shrikant Chaudhari, Technical Architect – Atos
By Madhuri Susarla, Partner Solutions Architects – AWS
By Ramesh Ranganathan, Partner Solutions Architects – AWS
 |
| Atos |
 |
Mainframe applications are often mission-critical, with significant business logic and large volumes of data.
There is a huge opportunity to move these applications to the cloud, allowing organizations to leverage benefits like cost reduction, improved agility, and the ability to unlock data to drive insights.
Atos, an AWS Advanced Consulting Partner and Managed Service Provider (MSP), classifies the mainframe migration dispositions into the following key categories based on customer requirements seen in the industry:
Re-architect: This pattern involves decomposing the legacy application functionality and then recomposing it back in the modern architecture, such as using microservices and cloud technologies.
Transcoding: This pattern involves line-based legacy code conversion to a modern language (like Java or C#). This is a like-for-like migration, which means there is no change to architecture and design of the application.
Re-platforming with mainframe emulator: Also known as re-hosting or lift and shift, this pattern involves moving the legacy applications to an emulator running on Amazon Web Services (AWS).
Migrating these applications to the cloud does have its challenges:
Little or no documentation and lack of subject matter experts (SMEs) with tribal knowledge.
High transformation costs due to the time taken to refactor or rewrite.
Testing the functional accuracy, data equivalence, and non-functional requirements.
There is a lot of information out there about the migration dispositions, but testing remains underrated. Testing needs to be comprehensive in case of the re-architect or transcoding dispositions, as the code base is completely new and needs to be tested like any new application.
Doing this manually is both effort-intensive and error-prone, and often the business knowledge required to develop test cases for the target system is incomplete or nonexistent. Automated testing solutions can help you establish functional equivalence between the old and new systems.
In this post, we will provide details of the Atos SyntBots solution to accelerate the testing of mainframe migration projects. We’ll also explore how establishing data and functional equivalence between the mainframe and migrated systems is made comprehensive and accelerated using this approach.
About SyntBots
SyntBots is a next-generation automation platform that utilizes intelligent automation to transform product engineering, ITOps, and business process across the enterprise.
SyntBots for product engineering combines agile development, environment automation, and a powerful set of reusable test automation tools to deliver continuous testing, continuous delivery, architectural compliance, and automated quality assurance (QA) across the entire enterprise development function.
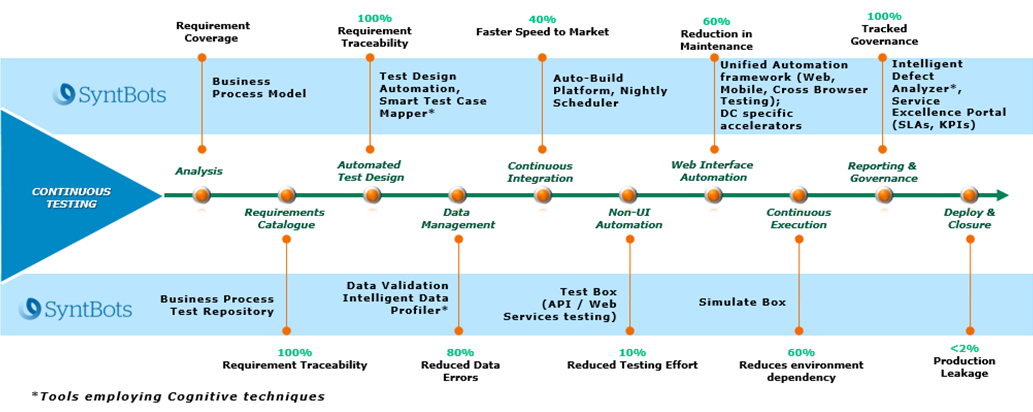
Figure 1 – SyntBots testing accelerators.
Process Recorder
The platform-agnostic Process Recorder captures user actions, automatically creates business process workflows, and performs analysis to identify processes for automation. The workflows generated are fed into the SyntBots TDA to generate test cases.
Test Design Accelerator (TDA)
Test Design Accelerator (TDA) auto-generates test cases from the business process (BPM diagrams) based on the functional specifications and requirements. SyntBots TDA enhances productivity of test design, test coverage, high reusability, and reduce SME dependency.
Hybrid Test Automation Framework (X-BRiD)
The X-BRiD test automation framework supports functional automation of web and mobile applications across browsers using Selenium, and performs non-functional testing such as accessibility and cross-browser testing. Intuitive object repository and data manager helps to maintain the test suite effectively.
Data Validator
Data Validator is a data migration testing tool that validates data in the source is migrated correctly to the destination by comparing/analyzing and pinpointing differences. It can connect various data sources like RDBMs, No SQLs, big data stores, cloud databases, flat files, and complex fixed width files. It’s also capable of checking if transformation of data occurs during movement of source data to destination using business rules.
Atos Mainframe Migration Process and Tooling
Atos, which holds AWS Competencies in Migration and Mainframe Migration consulting as well as Level 1 MSSP Security Consulting, has developed solutions to automate the various phases of mainframe migration, from application analysis to deployment.
For the transcoding disposition, which is the focus of this post, the following tools are used:
Automated migration of mainframe applications to modern cloud architecture is done using the Atos legacy migration solution: Atos Exit Legacy. This helps in analysis of code and database, migration of the code to modern languages, and in migrating the data.
Functional testing of the migrated application is performed using the SyntBots test design accelerator and test automation framework: X-BRiD. This framework supports functional testing on web applications across browsers. It maintains test cases and data, executes automated tests that cover regression testing, and generates test reports. It also provides a complete automation solution to test the migrated application.
Data migration and batch/transaction processing testing is performed by the Data Validator. It validates data before and after migration, as well as source and target outputs in batch or transaction processing.
The following table provides a phase-wise summary of tooling used by Atos in mainframe migration:
| Phase |
Objective |
Tool |
| Assessment |
Assessment of the existing application migration complexity by capturing data points like size, code complexity, and redundant code to create the business case. |
Exit Legacy – Inventory Analyzer captures code inventory and relevant complexity parameters. |
| Decompose |
Create documentation in the form of flow chart and sequence diagram by analyzing the code. |
Exit Legacy – Business Rules extraction tool auto-generated the design artifacts from code. |
| Recompose |
Source code is converted into the desired target technology (for example, OOP, Java, C#, or .NET). In this process, the COBOL code is broken down and put together in new technology in the form of different classes, methods, and functions. |
Exit Legacy – Rearchitect cleans up the source code and auto-generates the code in the target platform. |
| Validation – Planning |
Capture and enhance the business process based on SME interviews. Design the test cases based on process flows. |
Process Recorder captures user inputs and auto-generates linear flow of process. Meanwhile, SyntBots TDA auto-generates the test cases based on enriched process flow. |
| Validation – Functional Testing |
Functional/regression testing performed by comparing results between old and new application. |
Automated execution of test scripts and test run reports are generated using the X-BRiD hybrid test automation framework. |
| Validation – Data Equivalence |
Data is validated to ensure migration of data is error-free and batch programs are working fine. |
Validate the data migrated to target systems; files produced by batch programs via the Data Validator. |
About Atos Exit Legacy
Exit Legacy is Atos’ patented tools platform that hosts more than 35 tools to accelerate end-to-end application modernization.
Exit Legacy enables modular, accelerated, and de-risked modernization across modernization project lifecycle. It includes tools for automated legacy analysis, business rules extraction, interactive wizard-based language re-architecture enabling microservice creation from monolith legacy code, user interface (UI) modernization, data and database migration, data masking, code optimization, cloud enablement and containerization, and validation and ecosystem modernization.
Exit Legacy is used during the modernization process, and there is no lock-in post modernization.
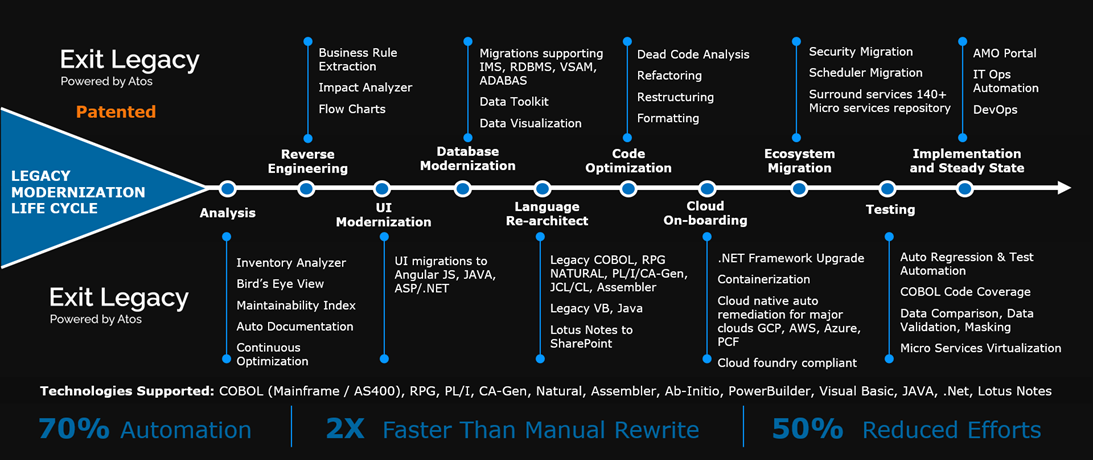
Figure 2 – Exit Legacy platform for transformation.
Sample Application Overview
The sample application considered for this post is an “employee master maintenance” application consisting of OLTP functionality developed in CICS/COBOL, and a batch program developed in COBOL/JCL. This application has a simple CRUD functionality with some basic validations.
The application has a main employee menu leading to employee master maintenance, department master maintenance, and designation master maintenance screens. The application data is stored in DB2 tables; namely employee, department, and designation. The full source code for this application can be found on GitHub.
As you can see in Figure 3 below, when the Exit Legacy – Inventory Analyzer tool is run, it provides a clear view of the application inventory like number of COBOL programs, number of copy books, CRUD operations mapping, and cyclometric complexity. This information is used estimate effort for rewrite and application testing, which is an input to the business case for the mainframe migration initiative.

Figure 3 – Application analysis with Exit Legacy.
Migrating the Application Using Atos Exit Legacy
The sample application is migrated using the Exit Legacy – Rearchitect tool and data migration utility to a modern web application with an HTML frontend, Java Spring middle tier, and MySQL database. The code generator has the capability to suggest multiple code patterns, and the developer can choose the one that fits the needs.
The source code for the migrated application can be found on GitHub as well. This code is now ready for deployment on AWS.
The figure below shows mapping of the old code and generated code for one of the designation master screens and its associated application logic.
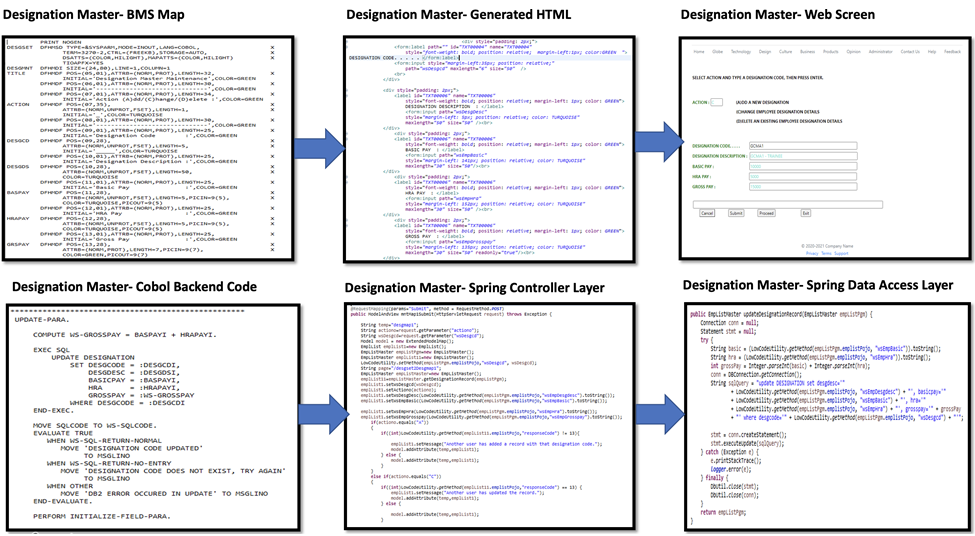
Figure 4 – Code generation for online application to Java web application.
The sample application also includes a batch program that extracts a comma separated (CSV) file for employee, department, and designation master tables periodically as part of an interface requirement with other third-party applications that need this data.
Exit Legacy converts the COBOL program into Spring Batch Job and Job Control Language files (JCL) to Spring batch configuration files. The image below shows mapping of the old code and generated code for one of the batch programs.
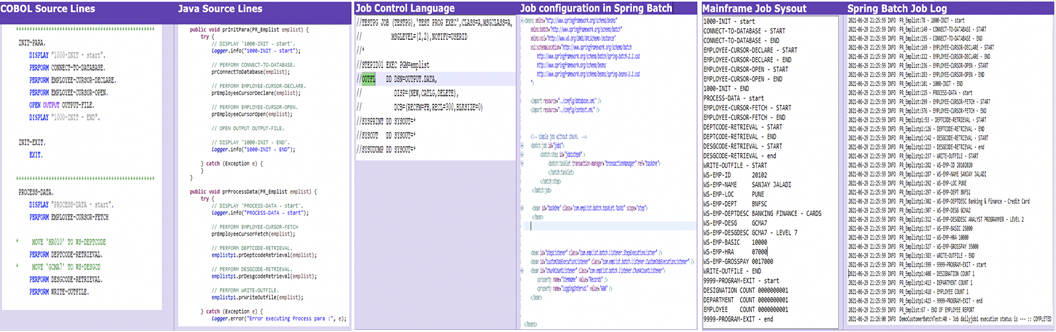
Figure 5 – Code generation: mainframe batch application to Java Spring Batch.
Validating Functional Equivalence of Migrated Application
While moving from legacy (mainframe) to a modern platform, it’s essential to ensure functionality is maintained as the application is completely re-architected and rewritten. The functional equivalence is evaluated by testing the scenarios in both platforms and comparing the results.
In this step, we record functional flows from Exit Legacy and leverage tools to automate the functional validation of the migrated application.
Process Recorder captures the user actions and translates them to functional process flow. These process flows are enhanced with manual inputs from application SMEs.
Test cases are automatically generated through SyntBots TDA. Optimized test cases are identified and considered for test script creation.
X-BRiD executes the automated web application functional testing on the migrated application. The identified test scenarios are scripted for automated execution. This framework minimizes the efforts required for creation and maintenance of automation scripts, and incorporates high degree of reusability by externalizing and maintaining the object repository and data manager.
Automated test scripts are run against a modern web application platform and obtains the test results.
Similarly, test cases are executed at the mainframe application as well, either manual or through third-party automation tool.
Comparison of the output against the mainframe application is manual in this example scenario. In practice, this is mostly likely the case due to lack of test automation on mainframe.

Figure 6 – Test case and test script generation.
Once the test scripts are created, then automated test execution and visibility of the testing progress become equally important.
The user interface-enabled test automation framework provided by X-BRiD helps to plan, manage, and execute scripts effectively. It also provides hassle-free maintenance by enabling externalization of test data and intuitive object repository.
Live reporting provides the execution progress and execution reports provides detailed step level report.
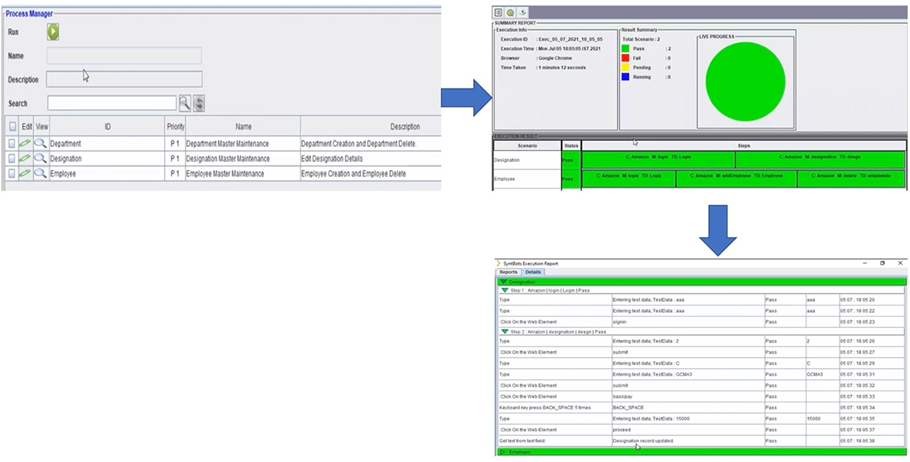
Figure 7 – Test execution and reporting.
Validating Data Equivalence of Migrated Application
Data equivalence testing in mainframes broadly has two categories:
One-time data migration validation, which is validating data from source application in mainframe (like DB2, VSAM datastores) to modern data stores (like Amazon RDS or Amazon Aurora).
Validating the data files produced or database updates made by batch programs that run periodically.
Validating Data Migration
In our sample application, the mainframe data is maintained in DB2 and the migrated application data maintained in MySQL. SyntBots Data Validator (data migration testing tool) validates that the data in the source (DB2) is migrated correctly to the destination (MySQL) by comparing/analyzing and pinpointing differences.
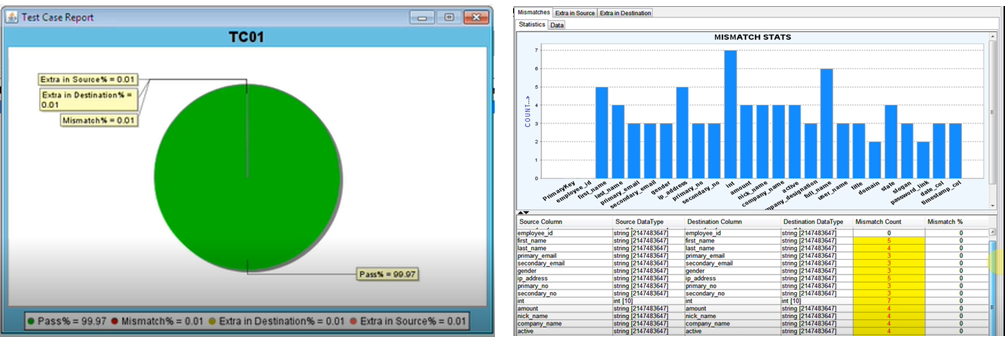
Figure 8 – Data validation summary results.
The execution result can be viewed for both source and destination file/database as:
Number of passed records and total number of records extra in both source and destination database.
Total count of mismatch records, mismatch values in source, and destination database.
Status of execution as pass or fail.
Validating Batch File Interface
For our sample application scenario, we’ll test the file output produced by the mainframe application against the file output produced by the Spring batch application.
The appropriate process flow is created for batch application, and test scenarios are identified by SyntBots TDA for these batch application processes. Batch processes are executed at the mainframe as well as on the migrated application.
Both output files are fed into the Data Validator tool to find the data mismatches, if any, between legacy and modernized Java batch.
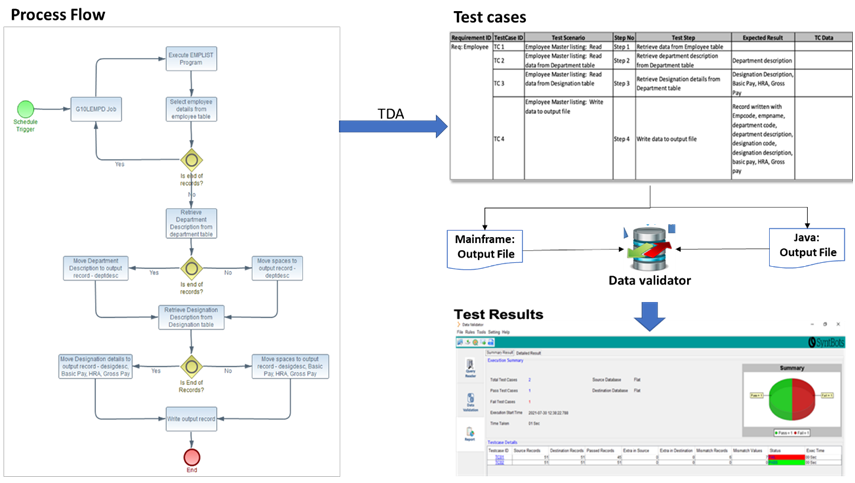
Figure 9 – Batch process validation.
Customer Benefits Achieved
Leveraging the AWS Cloud with the migration and automated testing tools outlined in this post, Atos has seen following benefits across customers:
70-90% reduction in application analysis by leveraging the automation provided by Exit Legacy – Inventory Analyzer, Exit Legacy – Business Rules, and SyntBots Process Recorder.
50-60% reduction in test design and script maintenance efforts leveraging SyntBots TDA to autogenerate the test cases and the X-BRiD test automation framework.
~100% improvement in functional test coverage via comprehensive analysis provided by the tools as mentioned above; validation by application SMEs and automated test execution leveraging X-BRiD.
~60% reduction in deployment effort achieved through effective business rule extraction, automated code reviews, and suite of accelerators for test case generation and execution.
2X acceleration in time to deliver compared to a non-automated approach.
Conclusion
Testing is one of the biggest pain points in mainframe migrations. In this post, we detailed a testing solution built by Atos that is based on their proven Test Design Accelerator (TDA) and X-BRiD framework that are part of the SyntBots automation platform.
A number of steps are automated when using this solution, such as capturing the existing flows using SyntBots Process Recorder, generation of test cases on the modern system, generation and execution of test scripts, and comparison of test results. This is possible for both online and batch components typical of a mainframe workload.
Together with AWS and the Atos Exit Legacy platform, customers have an end-to-end solution to migrate mainframe workloads to the cloud after comprehensive verification and validation.
To learn more, please reach out to Atos about your AWS and mainframe migration requirements.
.

.
Atos – AWS Partner Spotlight
Atos is an AWS Competency Partner and MSP that is a leader in digital services and believes bringing together people, business, and technology is the way forward.
Contact Atos | Partner Overview
*Already worked with Atos? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.
Gaining Operational Insights of the Australian Census with AWS
=======================
By Ali Khoshkbar, Cloud Architect – AWS
By Aaron Brown, Principal Engineer – Shine Solutions
By James Ireland, Account Executive – AWS
 |
| Shine Solutions |
 |
In early August, millions of people took part in the 2021 Census across Australia, providing a comprehensive picture of the country’s economic, social, and cultural makeup.
The Australian Bureau of Statistics (ABS) ran the 2021 Census on Amazon Web Services (AWS), and insights into the performance and uptake of the Census were provided to the ABS.
Using an operational insights (OI) platform based on the Serverless Data Lake Framework (SDLF) provided business intelligence that helped inform the 2021 Census operations across the country.
The ABS received a large amount of traffic, with more than 9.6 million forms in total, of which 7.6 million were submitted online. The ABS needed to get high quality data insights to understand and respond to challenges affecting Census completion across the country, so they could allocate resources most efficiently.
This included gathering detailed information from field staff on details of the dwellings being visited, from specific follow-up instructions to safety hazards. Sharing this type of information between staff and managers provided clear insights into the conduct of the Census field work and minimized re-work for enumeration staff.
The OI platform—built in partnership with AWS Professional Services, Shine Solutions, ARQ Group, and the ABS—achieved this goal of providing near real-time insights into a very complex logistical activity.
In this post, we discuss the high-level architecture of the OI platform, and how it was able to pull data from multiple disparate sources and serve it to PowerBI and a single-page application (SPA).
We’ll dive into a specific aspect of the architecture, demonstrating a pattern of executing SQL in Amazon Redshift and using Amazon Aurora as a fast-caching layer to improve user experience and reduce cost.
Finally, we’ll discuss how AWS, Shine, and the ABS worked together to design, build, and operate a well-architected system that delivered business value for a workload of national importance.
Architecture
The operational insights platform needed to pull data from various sources, including the Census’ frontend website and serverless backend, ABS’ on-premises Oracle databases, an Amazon Connect-based automated call center, AWS security services, and more. It also needed to scale to handle large volumes of data.
There was a real possibility of a high-scale distributed denial of service (DDoS) incident on the Census, so the OI platform had to be able to ingest data generated from hundreds of thousands of connections per second. A serverless architecture was a natural fit for these requirements.
There are three main layers in a typical data lake: the ingestion layer, the storage and transformation layer, and the serving layer.
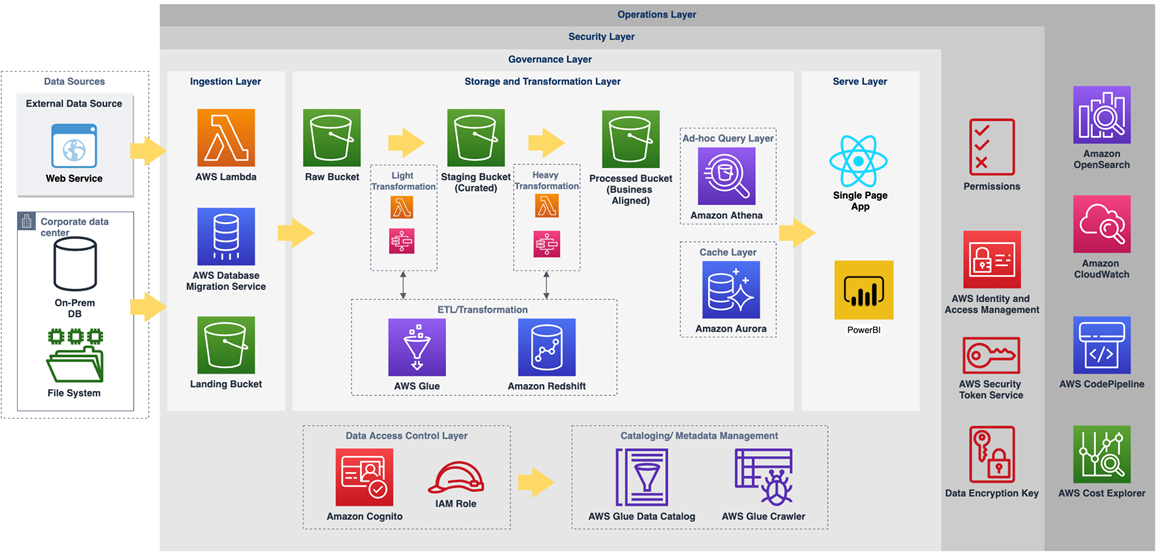
Figure 1 – The operational insights platform’s high-level architecture.
The AWS Database Migration Service (AWS DMS) was used to pull data from ABS’ on-premises Oracle databases and file systems for the ingestion layer. AWS Lambda was used to pull data from the Census Digital Service (CDS) and other sources. These services ingested data into Amazon Simple Storage Service (Amazon S3).
This is where services in the storage and transformation layer took over. AWS Step Functions was used as a workflow service to orchestrate Lambda functions which performed light transformations on the data. This included transformations like file format conversions (csv to Apache Parquet, for example), schema validation, and partitioning.
From here, heavier transformations, such as change data capture (CDC) processing using AWS Glue or complex business use cases were executed in SQL on an Amazon Redshift cluster. Using Amazon Redshift, AWS’ data warehouse service, these transformations could be run quickly and cost effectively.
For the serving layer, the OI platform needed to support many concurrent users, offer millisecond response times, and avoid a per-query pricing model to keep costs controlled. The decision was made to use a combination of Amazon Aurora and Amazon Redshift to achieve these three goals.
Amazon Aurora is a MySQL and PostgreSQL-compatible relational database built for the cloud and would use materialized views of the Amazon Redshift table to provide fast response times of less than 100ms.
Amazon Redshift would provide a significantly lower response time for complex queries that ran frequently or on demand on billions of records. These two services were configured within a PowerBI Gateway instance to allow PowerBI to access data from them. Data ran over AWS Direct Connect to ABS’ PowerBI instance, ensuring a high bandwidth throughput and consistent network experience.
A private react application (SPA) was built to provide OI administrators and users visibility on the OI platform operations itself. This application supports functionalities such as data lineage, transformation execution status and history, and some handy features like one-click datasets reloading to allow users to interact with the OI platform in an easy and transparent way.

Figure 2 – Example scheduled transformation dependent on two source transformations.
Amazon Redshift + Amazon Aurora
One of the patterns implemented by the OI platform was the use of Amazon Aurora as a caching layer for Amazon Redshift. Queries were executed in Amazon Redshift, then the results were stored in an Aurora instance.
In this pattern, transformations get executed on schedules in Amazon Redshift (every 20 minutes, for example) and the results are materialized and saved in Aurora Postgres using the dblink extension.
By making these results available in Aurora, performance improved significantly, with average access latency reduced from 2+ seconds on Amazon Redshift to ~100ms on Aurora.
Scalability is another important benefit of using this pattern. The OI platform can easily adjust to handle spike in the number of dashboard users by adding new read replicas in Aurora in just a few seconds.
Working in Partnership
The development of the OI platform demanded a fast pace, with business and development teams working together closely to deliver the right outcomes.
With involvement from four different organizations—ABS, AWS, Shine Solutions, and ARQ Group—this could have been very complicated. However, the four groups came together to make sure the result was effective, user friendly, and well-architected.
The team divided the work such that AWS and Shine built the underlying platform, ingestion processes, ordered SQL processing engine, data integrity checks, and developer tooling for the SQL transformations. Meanwhile, ARQ supported the development of the initial PowerBI visualizations.
This allowed the ABS to focus on what they do best—understanding and running the Census.
Having ABS developers focus on the transformations resulted in a deep understanding of the use cases from the wider ABS organization. This ensured the transformations and reports provided in-depth analysis and delivered value across the board, from the executive to operational users.
Daily combined stand-ups facilitated close collaboration, as everyone involved was able to understand the ABS requirements and any pain points. This allowed the project to pivot quickly and adapt to changing use cases.
One such example was the implementation of additional ingestion, analysis, and reports based on the logs of the CDS. These were added late in the project to address a new reporting and monitoring requirement and accomplished due to the platform’s extensibility and close collaboration of AWS, Shine, and the ABS.
Outcomes
Using the operational insights platform, ABS business owners were able to get near real-time insights into metrics about the Census:
Form submissions
Uptake of the Census across the country
Even the comparison of online forms vs. paper forms broken down by local area
In 2016, these metrics were made available to business owners once every 24 hours. They were able to get these at a much higher frequency than previous Census events.
Using the OI platform, that frequency increased to once every 20 minutes, with more frequent updates possible but not required. This allowed the Australian Bureau of Statistics (ABS), an intensely data-driven organization, to make more accurate decisions at a much higher rate.
To learn more about running your data lake on AWS, visit the Analytics on AWS website.
.

.
Shine Solutions – AWS Partner Spotlight
Shine Solutions is an AWS Public Sector Partner that provides leading-edge AWS innovation for large enterprises and government.
Contact Shine Solutions | Partner Overview
*Already worked with Shine Solutions? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.
V3locity Delivers Business Agility and Transformative Digital Experience for Life and Retirement Carriers
=======================
By Paul Kelly, Sr. Vice President, IT and Managed Cloud Services – Vitech
By Ben Meyvin, Principal Partner Solutions Architect – AWS
 |
| Vitech |
 |
Group insurance companies provide supplemental health insurance products to employees through their employers.
This segment has strong long-term growth potential, but barriers to success exist for insurers saddled with inflexible legacy policy administration systems. These barriers include increasing competition, ever-higher expectations for customer service, demand for tailored products and solutions, and a complex regulatory environment.
The need for a modern, flexible core system is clear.
Prudential is a Vitech customer and one of the largest group insurance companies in the United States. Vitech is an AWS Partner with the Financial Services Competency and one of the leading providers of financial and benefit administration software.
Hobbled by its legacy administration systems, Prudential faced challenges with bringing new or enhanced voluntary benefits products to market quickly. It also struggled to provide a competitive user experience for all stakeholders: brokers, employers, plan participants, and their own employees.
Prudential wanted a customer-focused platform to position them for success. Prudential chose Vitech’s V3locity policy administration solution powered by Amazon Web Services (AWS) to grow their business.
“Updating to a modern platform has made us a better partner with brokers and agents,” says Paul Virtell, VP of Product Management at Prudential Group Insurance.
Vitech’s V3locity policy administration solution allows group insurance companies like Prudential to increase agility, accelerate speed to market, and improve customer experience. It provides the ability to seamlessly receive upgrades of the software releases in a secure operating environment, with high quality support from the policy administration solution provider.
With cloud-native technology optimized to run on AWS and a transformative suite of complementary applications that offer full lifecycle business and enterprise functionality, Vitech has been recognized by Gartner as a life and annuity policy administration leader for five years in a row.
V3locity Architecture
To enable long-term, future competitiveness for Vitech’s clients, V3locity includes a robust architecture focused on cloud-native elasticity, resiliency, security, and scale.
It’s built from the ground up on a microservices-oriented architecture, representing a high degree of modularity and componentization that provides both domain-specific and enterprise-wide capabilities.
Deployed natively on the AWS Cloud, V3locity consumes a broad and growing range of AWS services that we’ll discuss in this post.
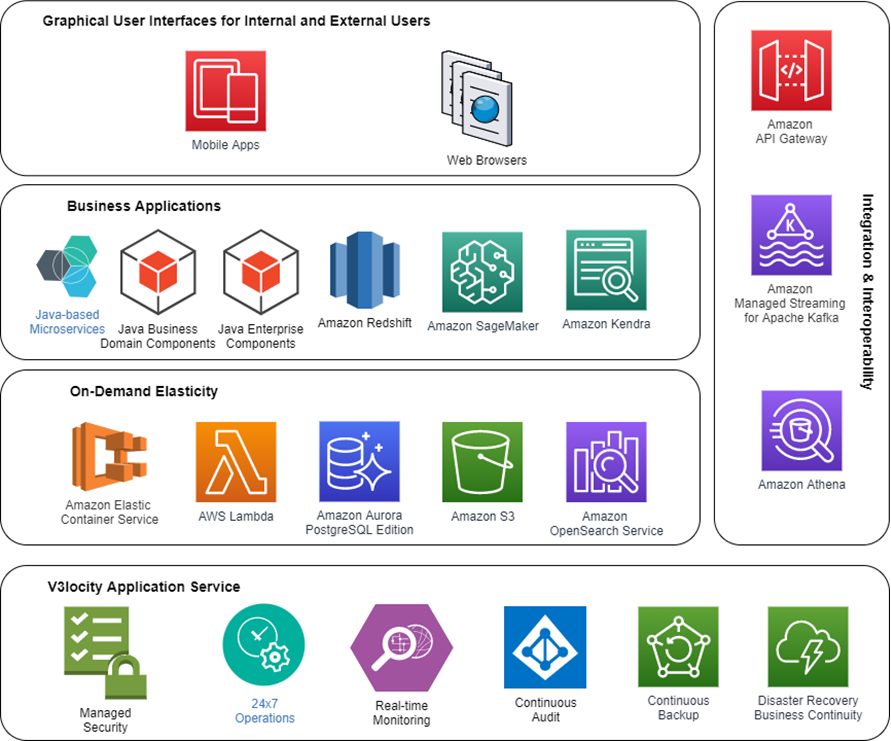
Figure 1 – V3locity technology stack and services.
The modularity and configurability of V3locity’s architecture has allowed Vitech to create a series of tailored experiences for a wide range of personas, including employers, employees, brokers, and insurance personnel. The result: the increased agility and better customer experience the group insurance market demands.
Digital experiences are configurable using business rules and according to individuals’ preferences. The digital experiences are data-driven, fully responsive, adaptive, and analytics-augmented.
End users interact with V3locity through single-page applications that communicate with the underlying components using REST and GraphQL. The combination of domain-specific and enterprise-wide microservices and a growing number of AWS services further enrich the capabilities of V3locity and V3locity’s digital experiences.
For example, Amazon SageMaker and Amazon Kendra power natural language, self-service capabilities. Amazon Textract provides advanced document image processing, Alexa for Business enables natural language processing, and Amazon QuickSight captures detailed usage analytics.
AWS Elastic Beanstalk, AWS Fargate, AWS Lambda functions, Amazon Aurora PostgreSQL, Amazon Simple Storage Service (Amazon S3), Amazon OpenSearch Service (successor to Amazon Elasticsearch Service), and Amazon Kinesis provide important infrastructure-level building blocks for V3locity components and digital experiences.
These include elastic computing with infrastructure automation, container-based and serverless deployments, as well as elastic storage for real-time and cost-effective management of relational and object-oriented data, real-time data streams, and full elastic indexing and search capabilities.
System extensibility and open interoperability help pave the way for the increased agility and faster speed to market required by group insurance companies.
V3locity’s extensive library of APIs are managed through the Amazon API Gateway, using Apache Kafka for message-based interoperability. Amazon Athena, Amazon Redshift, and AWS Database Migration Service (AWS DMS) enable real-time streaming and big data processing for data-level integrations.
V3locity uses a federated integration model to orchestrate Vitech’s cloud-native services and third-party services in the context of the relevant business activities.
The continuous information security advances and offerings made available by AWS help to harden V3locity and protect against information security risks.
V3locity protects the perimeter using AWS Shield Advanced, AWS WAF, and Amazon GuardDuty. V3locity is SOC 2, Type 2 compliant, which significantly reduces the regulatory burden for Vitech’s group insurance clients.
V3locity Application Service
Vitech delivers V3locity via the V3locity Application Service. Optimized for high performance on the AWS Cloud, the integrated platform approach results in newfound business agility and a rapid pace of innovation unavailable in on-premises, co-location, private cloud, or other deployment models.
Customers can rely on Vitech to manage the software directly for ongoing upgrades, troubleshooting, and overall production operations. Customers seamlessly receive upgrades of the V3locity software, releases, and security patches.
With direct access to the software on AWS, Vitech owns all troubleshooting and production support requirements for the V3locity software. This enables you to focus on delivering differentiated value to your own customers.
The V3locity Application Service gains much of its agility and extensibility from V3locity’s microservices-oriented architecture. V3locity services can be deployed and scaled independently, providing clear segregation between business domain-specific services and cross-cutting services such as exception tracking, logging, health checks, externalized configuration, and distributed tracing.
V3locity architecture also provides strong service-level fault isolation, significantly improving overall system resilience.
Microservices provide many advantages, but managing a sophisticated, distributed platform like V3locity is not trivial.
Tracking inter-process communications that traverse multiple, distributed services, assuring data consistency, minimizing latency, and optimizing scaling in a microservices architecture can present significant operational complexity for IT teams. The V3locity Application Service handles all of this complexity while providing full transparency to V3locity users.
Unlike with on-premises, co-location, private cloud, or other policy administration deployment models, you can focus more on your business and no longer worry about a wide range of complex platform and infrastructure services.
Vitech and AWS Collaboration
As an AWS Competency Partner, Vitech has access to a wealth of expertise and support from AWS to build a Well-Architected solution and to innovate using AWS services and capabilities. For Vitech’s customers, this means they can rely on V3locity to comply with the design principles of security, reliability, performance, operational excellence, and cost optimization.
Vitech fosters continuous close collaboration and training with AWS teams. Customers, in turn, benefit from expert-level knowledge of AWS services developed by Vitech’s engineering team. This is particularly critical since V3locity is delivered as a fully managed, hosted service.
The AWS Financial Services Competency is a forward-looking program that anticipates industry trends. Dedicated insurance domain experts and solution architects on our joint Vitech and AWS team continue to innovate on your behalf, delivering a transformative suite of complementary applications that offers full lifecycle business functionality and robust enterprise capabilities.
Innovation at a Faster Clip
The V3locity Application Service includes ongoing upgrades to the included V3locity services, including the digital experiences, components, and underlying AWS infrastructure.
Vitech uses its AWS lab environment as an innovation hub. Vitech has recently created prototype versions of new AWS-enabled V3locity cloud services that include:
Amazon Textract for advanced optical character recognition technology that generates smart validations and automated data extraction from non-digital data formats via machine learning.
Amazon SageMaker for predictive modeling in areas like recommendations to group insurance employers and employees and user journey analytics.
Alexa for Business and digital bots for common self-service activities like retrieving information.
AWS Audit Manager to continuously audit AWS usage for compliance with regulations and industry standards.
AWS Security Hub to perform security best practice checks, aggregate alerts, and enable automated remediation.
Amazon Detective to analyze, investigate, and quickly identify the root cause of potential security issues or suspicious activities.
Summary
Group insurance companies need to provide higher service levels to their stakeholders—employers, employees, brokers, other ecosystem partners, and their own insurance personnel—to remain competitive.
Modernizing policy administration has become a high priority focus area because of the positive impact on user experience, accelerated speed to market, and overall agility.
Using Vitech’s V3locity Application Service allows group insurance companies to exceed the necessary service levels (short-term and long-term) while offloading the management of the associated application and infrastructure services to Vitech, through its collaboration with AWS.
With V3locity, group insurance companies can receive ongoing software upgrades seamlessly and focus significantly more time and resources on growing their businesses.
.

.
Vitech – AWS Partner Spotlight
Vitech is an AWS Financial Services Competency Partner and one of the leading providers of financial and benefit administration software.
Contact Vitech | Partner Overview
*Already worked with Vitech? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.
How OppSync Integrates CRMs with ACE Pipeline Manager to Enable Co-Selling
=======================
By Daniel Martinez, Lead Software Engineer – Ibexlabs
By Yash Kimanti, Software Engineer – Ibexlabs
 |
| Ibexlabs |
 |
Every business has unique ways to approach the sales process. One commonality, however, is that customer data is an important driver to make a sales process successful.
To help businesses get the most out of their customer data, customer relationship management (CRM) tools are used widely to manage data throughout the customer journey.
In the sales process, organizations need to update the CRM with customer data to keep track of opportunities. It’s a challenging task, and some businesses keep a dedicated team to maintain it. The challenges become even more cumbersome when there’s a need to deal with multiple CRMs simultaneously.
In that case, the exchange of data between two CRMs should be seamless and glitch-free. For this, you need a level of technical proficiency to regularly update customer data on your CRM. These opportunities, in the form of fluctuating data, need to have a single source of truth between two systems. It’s a challenge to keep the data in sync all of the time.
For AWS Partners, the ACE Pipeline Manager is an exclusive benefit for participating members in the APN Customer Engagements (ACE) program. It provides organizations with full-service management of their pipeline of AWS customers, allowing for joint collaboration with Amazon Web Services (AWS) on those engagements.
In this post, we will discuss how various AWS services support Ibexlabs’ software-as-a-service (SaaS) solution, OppSync SPIM (Sales Pipeline Integration and Management), to better optimize and automate CRM integration with the ACE Pipeline Manager.
Ibexlabs is an AWS Competency Partner and Managed Service Provider (MSP) that provides next-generation solutions that equip customers for success on the AWS platform. Ibexlabs is also a security consultant partner helping many SMBs and startups in their cloud journey by focusing on security and compliance.
Challenges in Synchronizing Two CRM Systems
It can be challenging for businesses to ensure continuous data syncing between two CRM systems. When there’s an update on one of the CRMs and it doesn’t show on the other despite an integration, you need manual efforts to make this update.
One of the challenges during integration is assuring data is syncing to both CRMs, thus eliminating the need for manual intervention.
Other challenges may include:
Lack of scalability: While scaling, downtime may cause a delay in syncing up. Additionally, scalability involves several steps from the user’s side such as coding, software updates, and monitoring.
Improper administration: Maintaining two databases is a tough experience and may require coding to access a database at a technical level.
Downtime: Duplicate and mixed up data may cause inconsistencies that require additional time and effort for cleanup, resulting in downtime.
Security: Lack of industry-standard encryption may cause a threat to a user’s important data.
Syncing inconsistencies: It’s a challenge for users to maintain the data lifecycle and keep the integration updated from end-to-end.
Unable to share data pipeline: If a business is not able to share the data pipeline seamlessly, it may cause loss on shared opportunities.
CRM + ACE Integration with OppSync SPIM
A sales pipeline offers opportunity to visualize sales operations by focusing on potential buyers in progressive stages of their purchasing process.
With a sales pipeline, the sales team can measure how effective company sales efforts are when turning leads into customers. This data-driven process may require a company to integrate two CRM systems.
Designed using AWS services, OppSync SPIM (Sales Pipeline Integration and Management) from Ibexlabs integrates a partner’s existing CRM with the ACE Pipeline Manager without partners having to invest development time.
Users get instant notifications whenever there’s an update in either CRM systems. SPIM doesn’t save any data and takes security measures supported by AWS services to ensure privacy for the users.
AWS Partners can download a detailed report anytime. Additionally, it’s a no-code solution that means partners don’t have to put in effort towards its maintenance.
AWS Services Empowering OppSync SPIM
While designing the SPIM, Ibexlabs solved many challenges with the help of AWS services. In the diagram below, you can see the core architecture of OppSync and how AWS services such as Amazon ECS, AWS Lambda, and Amazon RDS were used to build the platform to help execute the sales pipeline integration.
AWS security services such as AWS KMS, WAF, and AWS Secrets Manager helped to ensure a strong security foundation for protection of customer information.
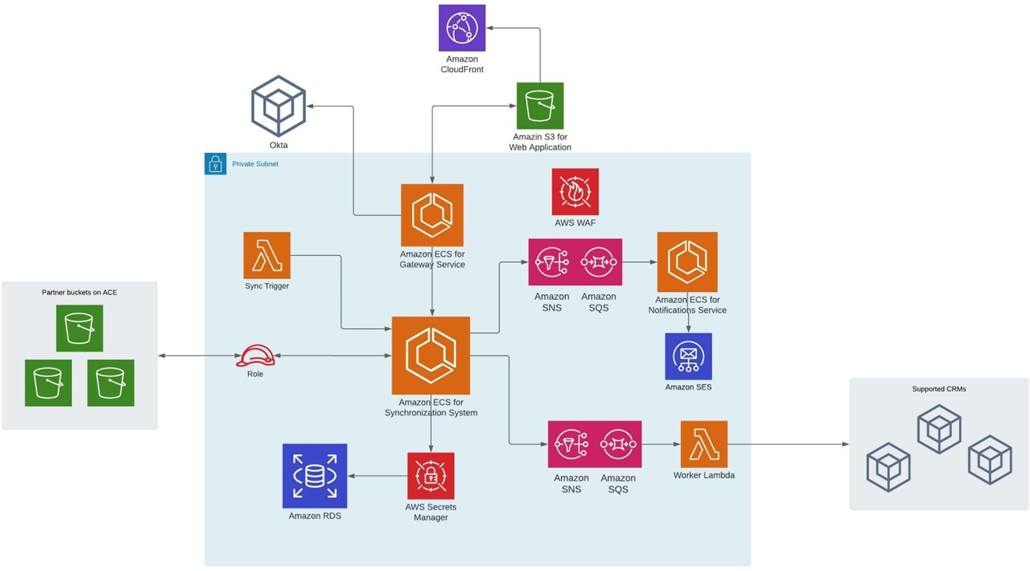
Figure 1 – Overview of AWS services behind OppSync SPIM.
Amazon ECS
Amazon Elastic Container Service (Amazon ECS) is a container orchestration platform that allows you to easily deploy any containerized workload in a serverless environment. You don’t need to maintain a control plane or node infrastructure common in other container orchestrators.
Early on, OppSync deployed most critical workloads on Docker through Amazon ECS, as the compute model provided by AWS Lambda didn’t fit a use case where Ibexlabs needed to continuously communicate with the many third-party systems OppSync had integrations for.
AWS Fargate, when used with Amazon ECS, is a fully managed compute engine that can be scaled up and downsized as needed. This elasticity is especially relevant to OppSync’s core engine as it needs to process and transmit variable amounts of data periodically to third-party systems through the integration it supports.
Another important feature of ECS that OppSync leverages is the ability to deploy as many instances of a given service as needed. This allows OppSync to distribute the requests between the replicas and ensure no single service gets overwhelmed with requests and becomes a single point of failure.
Features like high availability, elasticity, and concurrency led Ibexlabs to use Amazon ECS to deploy core parts of the OppSync solution, and drove the team to leverage Lambda for other critical system needs.
AWS Lambda
AWS Lambda is a serverless compute service that lets you run code without provisioning or managing servers and runtimes. It continuously scales, maintains a consistent performance at any scale, and optimizes for cost-efficiency.
OppSync uses Lambda to deploy several data processing pipelines that need to be run concurrently to transform and transmit massive amounts of data ingested from various sources into other target systems.
To enable the synchronization capabilities between ACE and users’ CRMs, OppSync uses Lambda to process data generated in Amazon Simple Storage Service (Amazon S3) for many different users. This data can vary in size for different users and is a great use case for parallel processing.
Another important aspect of this workflow is loading the data extracted and transformed from ACE into the different CRMs. By using Lambda, OppSync can easily parallelize this workload and have each invocation process different datasets for different AWS Partners at the same time without disrupting the service.
The team at Ibexlabs can iterate faster because Lambda supports sharing code between different functions by packaging it into a .zip file and uploading as a Lambda layer.
This lets OppSync share a common framework and toolset between functions, thus allowing developers at Ibexlabs to focus on writing actual business logic of product and not reinvent the instrumentation and abstractions they have already defined and tested through time.
Amazon SNS and Amazon SQS
Amazon Simple Notification Service (SNS) and Amazon Simple Queue Service (SQS) are fully managed messaging services that implement a pub/sub communication and queueing system, respectively. Ibexlabs uses both services extensively to integrate various services and Lambda functions together.
By combining SNS and SQS, Ibexlabs can compose different services to create event-driven architectures that scale seamlessly. Since both services are fully managed, they are able to allocate resources as needed.
The key SNS feature leveraged by OppSync is the ability to spread messages to a large number of consumers to process messages in parallel. This allows the tool to batch and transform the data between supported integrations with efficiency.
To ensure resilience and apply backpressure when processing data is sent through SNS, OppSync leverages SQS to buffer messages. Because of this, a given service does not get overwhelmed by bursts of requests as it processes one message at a time.
To add another layer of redundancy, OppSync leverages SQS dead-letter queues to reprocess requests that failed in reaching their destination.
Overall, SNS and SQS are fundamental pieces that let Ibexlabs build scalable and resilient architectures while driving down costs to a fraction of the usual price when compared to managing such infrastructure ourselves.
Amazon RDS
Amazon Relational Database Service (Amazon RDS) is a managed service that enables OppSync to provision, manage, and scale a relational database.
Ibexlabs chose Amazon RDS early on during planning due to its ease of use and the ability to create high-performance replicas they could leverage to offload reads easily.
A key aspect of RDS that works in conjunction with replication is the ability to scale up and down resources with minimal downtime. This makes for an ideal disaster recovery setup, as OppSync can quickly promote a replica to be the main database and scale its resources in a matter of minutes to maintain our services.
Lastly, the ability to isolate databases within a virtual private cloud (VPC) and encrypt data at rest and in transit makes it ideal for this use case, as customer data privacy is a top priority for Ibexlabs, including the metadata stored on their databases.
AWS Key Management Service
Security, privacy, and regulatory compliance are top priorities as Ibexlabs needs to process users’ confidential business data. To address these challenges, the team leverages AWS Key Management Service (KMS), which is a fully managed service that makes it easy to create, manage, and use cryptographic keys across multiple AWS services.
Data encryption both at rest and in transit is important because users trust Ibexlabs with sensitive business information. The team leverages KMS to generate encryption keys for all of the services where data are stored.
Ibexlabs can audit the usage of those keys by leveraging AWS CloudTrail’s integration with KMS and meet regulatory requirements.
Web Application Firewall
AWS WAF is a managed firewall solution that helps secure applications against common attack patterns such as SQL injection or cross-site scripting. It allows you to create your own rules to block and filter traffic, and also provides a monitoring dashboard where you can have real-time visibility into your application’s web traffic.
Ibexlabs leverages AWS Managed Rules for AWS WAF extensively to guard OppSync against OWASP Top 10 security risks and other less-known ones. Since it provides robust monitoring and altering capabilities, Ibexlabs has set up alerts for any unwanted traffic pattern to help detect such traffic patterns and to enact an immediate mitigation plan.
Overall, the team at Ibexlabs likes the ease of use by which they can add or delete rules to block requests from certain regions or certain patterns detected, such as bots performing automated spamming.
Conclusion
Introducing a suitable technology empowers businesses to connect with potential buyers and convert them into opportunities.
In the sales pipeline, a buyer goes through various stages in the purchasing process and every stage has corresponding data. CRM systems manage this customer data, but sharing data between CRMs can be routinely difficult.
Ibexlabs used various AWS services to develop the OppSync SPIM platform and enabled the integration of users’ CRMs with the ACE Pipeline Manager with near real-time data syncing capabilities. This process helps AWS Partners by eliminating duplicate efforts when managing two sales pipelines.
The content and opinions in this blog are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
.

.
Ibexlabs – AWS Partner Spotlight
Ibexlabs is an AWS Competency Partner and MSP that provides next-generation solutions that equip customers for success on the AWS platform.
Contact Ibexlabs | Partner Overview | AWS Marketplace
*Already worked with Ibexlabs? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.
Transform Your Business with Smart IoT Solutions and Lenovo’s Think IoT on AWS
=======================
By Rakesh Kumar, Director, SW Engineering – Lenovo
By Ryan Vanderwerf, Partner Solutions Architect – AWS
By Gandhinath Swaminathan, Partner Solutions Architect – AWS
 |
| Lenovo |
 |
Internet of Things (IoT) technologies measure physical environmental parameters and convert them into a digital signal for better interpretation, either on edge or in the cloud.
Such digital signals are used to automate the workflow, provide business insights, and improve customer experience without any human intervention. IoT use cases that use these digital signals range from counting retail store visitors and automating inventory management to a touchless self-checkout process.
The touchless self-checkout process requires integration of several IoT solutions, such as contactless payment, touchless inventory, and computer vision, to provide the best customer experience.
Most business modernization initiatives require integration of several IoT devices and solutions. These integrations require businesses to select, validate, adopt, and manage various IoT solutions.
Managing solutions from various vendors with different security architecture, network topology, ways of managing the device lifecycle, and even approaches to post-deployment services can be a significant challenge.
Enterprise customers need a marketplace experience to address the complexity of integration IoT solutions, and to provide a single point of contact for solution validation, deployment, and post-deployment services.
Lenovo Solutions Management Platform hosted on Amazon Web Services (AWS) provides a marketplace experience for enterprise customers to procure validated solutions. It empowers solution providers (ISVs) to commercialize and scale their products across the globe.
In this post, we will discuss what the Lenovo Solutions Management Platform is and how it was built to monitor your solutions. Customers and ISVs can monitor millions of devices and have confidence their solutions will be monitored and supported.
Solution Overview
The Lenovo ThinkIoT Solutions Management Platform provides managed services to proactively monitor and manage the solutions deployed at customer sites. It is an outcome of industry knowledge, experience, and deep research of industry needs.
The ThinkIoT platform provides a user-friendly experience for service providers to onboard and configure solutions, customers, and devices. It’s a reliable, secure platform hosted in multiple AWS Regions including China, Asia Pacific, EMEA, and North America.
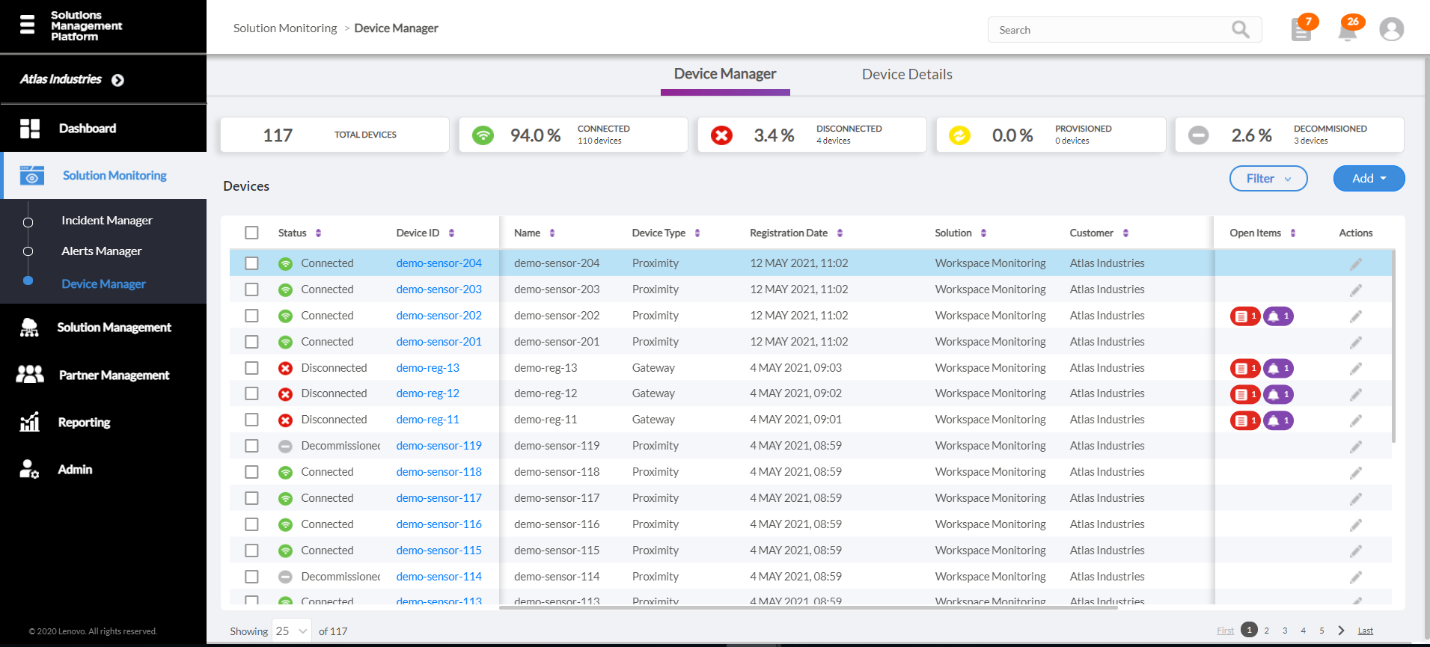
Figure 1 – Lenovo Solutions Management Platform device administration.
Services used:
AWS IoT Core
Amazon Kinesis Data Streams
Amazon Kinesis Data Analytics for Apache Flink
Amazon EventBridge
The following high-level architecture diagram represents the telemetry data ingestion architecture of the Lenovo Solutions Management Platform.
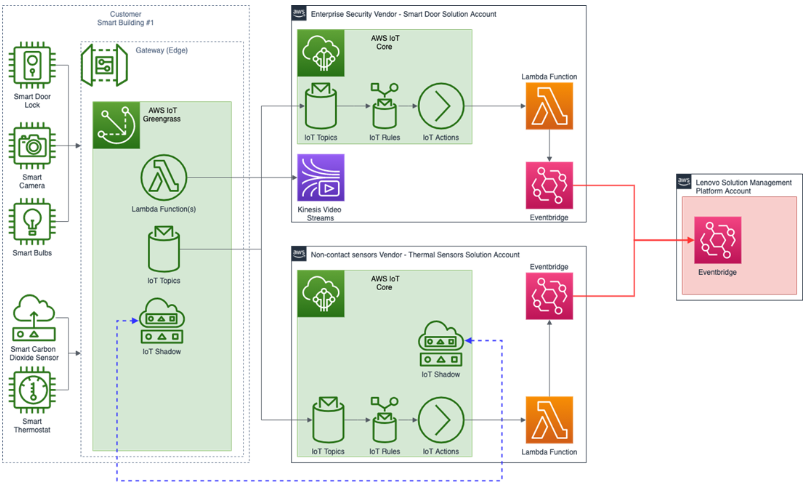
Figure 2 – Typical AWS IoT customer integration with Lenovo Solutions Management Platform.
Lenovo Solutions Management Platform uses Amazon EventBridge to integrate with vendor/partner AWS accounts.
A public EventBridge endpoint is provided with all required credentials to securely integrate with a vendor’s AWS accounts. This endpoint will be used by the Solutions Management Platform to subscribe to the data about IoT devices, their configuration, and telemetry stream.
EventBridge also allows for non-IoT solution monitoring for critical systems that may need to be monitored with the Lenovo platform.
Getting Started
The following steps are required to integrate existing AWS IoT Core solutions with the Lenovo Solutions Management Platform:
Contact the Lenovo platform team at devopssmp@lenovo.com to gather the required credentials and installation script to onboard your solution.
The Lenovo platform team will onboard the solutions and provide the customized installation script with access rights to publish data on the Lenovo EventBridge.
Run the installation script in the vendor’s AWS account to create a local EventBridge and connect it with the Lenovo EventBridge. The script will also deploy an AWS Lambda function to forward the telemetry data from the vendor’s AWS IoT Core to the vendor’s EventBridge.
Provide a list of devices to be provisioned in the Lenovo Solutions Management Platform for monitoring purposes. The platform will only monitor and manage the provisioned devices and ignore all other devices, data, and information.
The Lenovo platform team will connect with you to provide step-by-step instructions after receiving your inputs.
Real-Time Analytics and Alerting
The Lenovo Solutions Management Platform will monitor device and ISV cloud solution health. It detects service and device anomalies by capturing and analyzing telemetry data in near real-time.
Anomaly detection and the comprehensive rules engine is written in Java using Apache Flink managed by Amazon Kinesis Data Analytics.
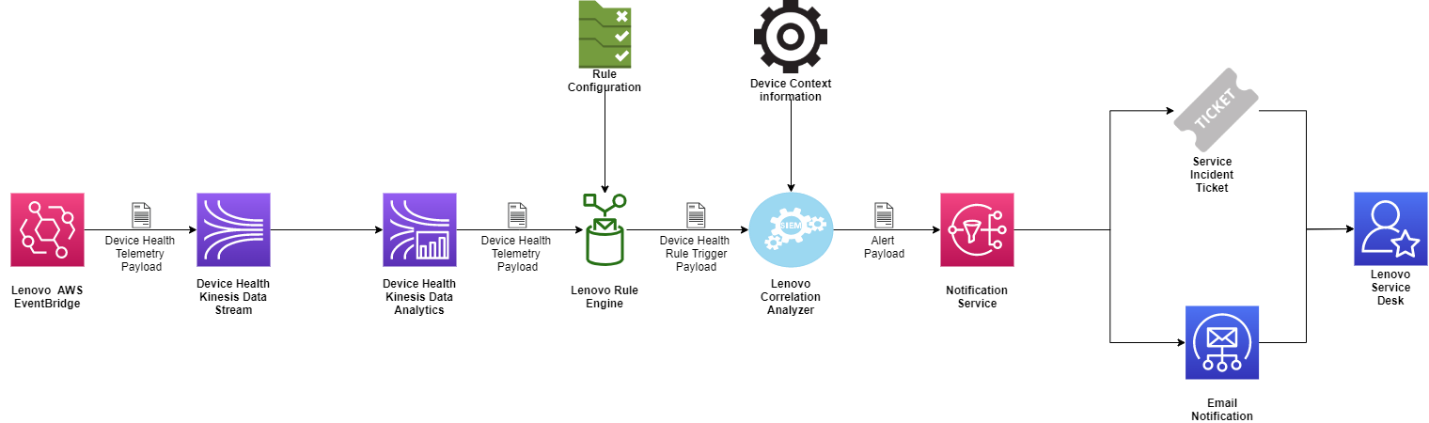
Figure 3 – Anomaly detection with the Lenovo Solutions Management Platform.
Anomaly detection is configured using rules that can be a simple logical condition or more complex, requiring data aggregation windows.
Lenovo’s rule engine allows for the creation of dynamic rules on aggregator windows of various sizes and supports various statistical aggregate functions. The platform also provides composite rules through an intelligent correlation analyzer to deduce the relationship between alerts. This increases the precision of the service incident tickets.
Such correlations help service personnel to analyze the root cause by differentiating a device failure from the network and infrastructure problem. Lenovo’s platform notifies the service team by auto-generating a service ticket.
Customer Success Story: Relogix
Relogix is a Lenovo trusted solution partner that provides smart, flexible workplace solutions. It’s one of the solutions currently validated and verified by the Lenovo Industrial Solution team and integrated with the Lenovo Solution Management Platform.
With a combined 25 years of domain expertise, state-of-the-art occupancy sensors, and the Conexus Workplace Insights Platform, Relogix helps transform global real estate portfolios, corporate strategy insights, and improve employee experience, productivity, and well-being while optimizing global spend on CRE portfolios.
Relogix combines data analytics with a variety of sensors, such as occupancy sensors and people counters, which interact with a local gateway to forward on workspace or conference room occupancy and floor-level occupancy to services hosted in the cloud.
The data is analyzed by Conexus and delivered in an easy-to-understand dashboard that provides business insights about workspace utilization and improves the employee experience overall.
The Lenovo Solutions Management Platform provides managed services by continuous monitoring of these devices and sensors deployed across various geographic locations, including North America, United Kingdom, and APAC.
“We know what it’s like to feel like you have a blind spot when it comes to understanding how your space is used, and we’re committed to making workplace analytics easier than ever,” says Andrew Miller, CEO at Relogix. “Through our global partnership with Lenovo, we’re able to make the challenging work of today’s corporate real estate leaders that much easier.”
You can learn more about the AWS, Lenovo, and Relogix solution by watching this on-demand webinar.
Conclusion
The Lenovo ThinkIoT Solutions Management Platform brings together validated ISV solutions on AWS to provide a marketplace experience for customers trying to embrace IoT solutions.
The platform helps ISVs to globally scale their operations and accelerate time to market by providing a holistic service management experience.
.

.
Lenovo – AWS Partner Spotlight
Lenovo is an AWS Partner and global company for the IT, x86 server, PC, and other computer peripheral devices.
Contact Lenovo | Partner Overview
*Already worked with Lenovo? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.
Get a Blockchain App into Production Fast with Hyperledger Fabric and Kaleido
=======================
By Jim Zhang, Co-Founder and Head of Protocol – Kaleido
 |
| Kaleido |
 |
Ever since its launch in 2015, Hyperledger Fabric has been a top blockchain protocol choice for enterprise use cases that require a permissioned blockchain network.
Fabric is well designed based on a modular architecture that supports the full spectrum of levels of decentralization, so it’s no surprise that multiple blockchain-as-a-service (BaaS) platforms exist that support Fabric.
However, most of these platforms target the fully decentralized governance model, with all members being equal. This makes critical procedures such as onboarding a new organization, creating a channel, or deploying chaincodes a complex process of collecting signatures and votes from multiple stakeholders.
As a result, enterprises often struggle to actually get into production with Fabric on these platforms.
Kaleido, on the other hand, makes provisioning a Hyperledger Fabric blockchain network dramatically simpler.
Kaleido, which is available on AWS Marketplace, is built on the philosophy that a Network Operator role is critical to the success of today’s enterprise consortiums. Rather than trying to force consortiums to fit into an ideal model that does not reflect the practical challenges existing today, this approach helps consortiums succeed in the real world, and get their apps into production faster.
The Case for Network Operators-Centered Design
Before diving into the Fabric support on Kaleido, we first need to understand the Kaleido platform’s design philosophy that is centered around the Network Operator role.
While blockchain protocols solved the technical challenges with governance, making decentralization the foundation of transaction finality and data immutability, in real-world consortiums an organizational governance model is still a separate piece of the puzzle independent of the blockchain protocol.
Using an example, ERC20 is a popular standard for non-fungible tokens (NFTs) with hundreds of deployments on Ethereum mainnet alone.
While Ethereum mainnet itself is fully decentralized, with tens of thousands of block mining nodes, most ERC20 tokens deployed on Ethereum mainnet employ a centralized governance model. The prevalent practice is that the deployer of the token contract is given special privileges to become one of the select few, sometimes the only, identities who can mint new tokens.
This is not a scam scheme but a reflection of the need for a governance model that makes things work in the real world.
Now, let’s zoom in on the world of enterprise consortiums. From working with hundreds of companies both large and small—including many leading consortiums for industries like healthcare, insurance, banking, retail, global trade finance, manufacturing, and others—Kaleido has observed the dynamics of multiple companies and organizations that are often competitors trying to collaborate in a consortium setting.
A key observation is that for such consortiums to function and realize the promise of the peer-to-peer blockchain network, a central entity that defines and implements the governance policies is critical.
It’s important to note that a centralized governance model does not negate decentralization on other layers. For a detailed discussion on different layers of decentralization, check out this blog post on What is Blockchain Decentralization?
This design philosophy has led to some unique platform features on Kaleido compared to other BaaS providers. Any user on an appropriate subscription plan, either Business or Enterprise, can initiate a consortium and invite other organizations to join, which makes the initiator’s organization the designated Network Operator of the consortium.
This organization has the authority to delegate key privileges to the invited organizations, or choose to keep the privileges to themselves.
These privileges include the ability to:
Provision blockchain nodes that are permitted to propose blocks. Without this privilege, a member organization can only provision blockchain nodes that can replicate blocks proposed and regulated by other nodes.
Create and upgrade blockchain environments.
Invite other organizations.
Create multiple memberships in the consortium under their organization.
Deploy smart contracts.
Fabric support on Kaleido can leverage this governance model and streamline the complex processes involved in the key procedures, such as creating channels and deploying chaincodes.
Details on Kaleido’s Fabric Support
Node Deployment
To start off, as with the existing blockchain protocols, Kaleido supports a full range of node deployment options, including:
Fully managed cloud-based deployment with AWS across six regions (US east, US west, Europe central, Europe south, Asia north, Asia south) and three continents.
Self-managed cloud-based deployment with any cloud vendor.
Self-managed private data center-based deployment.
Raft is the only consensus algorithm available to choose from at the moment. Given the complexity of managing an Apache Kafka cluster and its centralized nature, the Kafka-based consensus implementation is no longer recommended.
As a practical limitation, given Raft consensus algorithm’s sensitivity to networking latency, all orderer nodes must be provisioned in the same region. Orderer nodes can only be provisioned inside a Kaleido region as fully managed nodes, but for peer nodes all deployment options are applicable.
Channel Management and Policies
All Fabric blockchain environments on Kaleido have a built-in channel that includes all of the member organizations and the orderer and peer nodes.
This is useful for application developers to quickly get started, as well as acting as a public utility channel holding global information and common utility chaincode services that are available to all the members of the environment. The name of the built-in channel is default-channel.
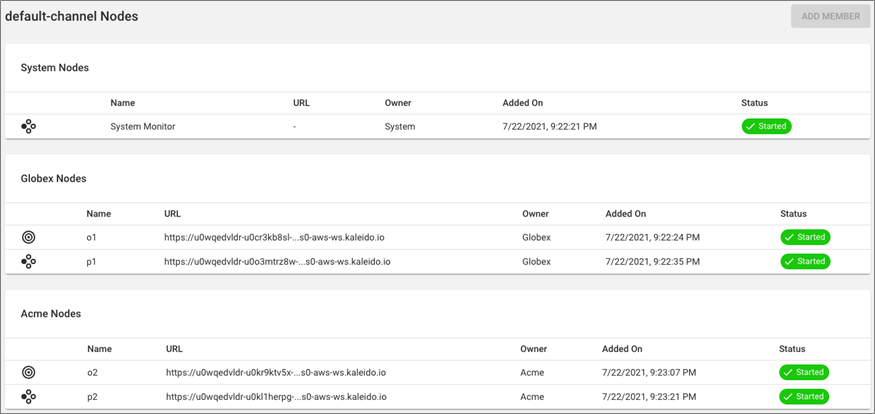
Figure 1 – Member organizations, orderer nodes, and peer nodes in the Fabric environment.
The design philosophy of the Network Operator-centered design is best reflected in the policies that Fabric channels in Kaleido are configured with by default. These policies are displayed in the details panel of the channel.

Figure 2 – Detail panel showing the Fabric channel’s default policies.
For the “Channel Membership Administration” policy, which governs approval of channel memberships, the formula is “OR('u0vgwu9s00.admin')”. The string ID “u0vgwu9s00” represents the membership of the channel initiator organization.
This policy gives the channel initiator organization the sole responsibility of adding or deleting channel memberships.
For the “Channel Consensus Administration” policy, the same formula is applied. This default policy is chosen to allow the member organization of the Network Operator role to effectively perform its duty vested in them by the general member organizations.
Of course, if the consortium takes a different shape and does not include a Network Operator role, then different policies can be applied. Support for specifying non-default policies including custom formulas is coming soon.
Chaincode Management
Chaincode management, including deployment and upgrading, is streamlined as well. This takes advantage of the platform-level smart contract management support in Kaleido.
A chaincode lifecycle starts with the chaincode developers, who develop and test the chaincode program. At some point, the program is deemed ready for review and approval by the technical committee of the consortium. Once approved, the contract code must be uploaded to the consortium for version management and deployment to individual environments and channels.
The Kaleido smart contract management allows the Network Operator, or any other member organizations that have been delegated with the “Manage Smart Contract” privileges, to upload Fabric chaincodes to the consortium’s shared storage. This makes it visible to all member organizations.
For this step, an app project must first be created. Two types of chaincode implementations are supported:
Golang binary: This must be the binary executable compiled from the golang chaincode.
Node.js project: This must be the project that contains a node.js application with a package.json describing the module details. The module can be written in JavaScript or typescript.
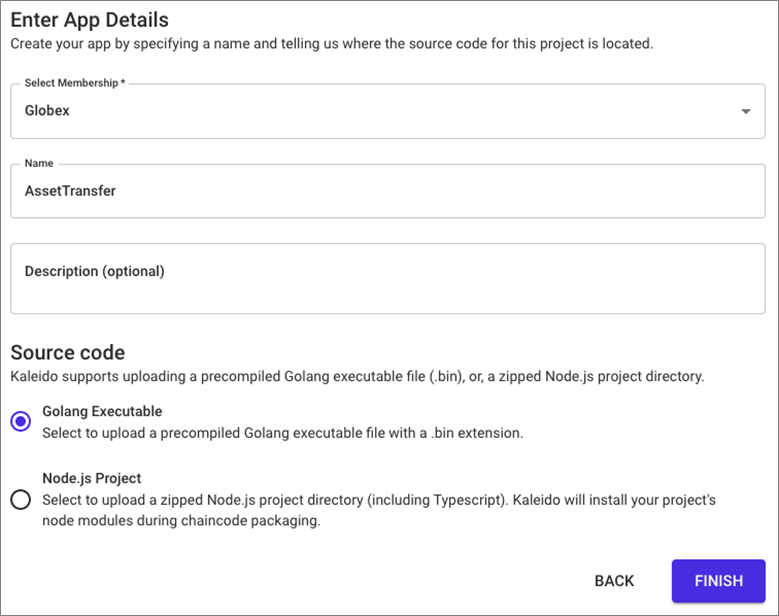
Figure 3 – Select the chaincode type planned for deployment in the app project.
Inside the chaincode project, deployments are uploaded and versioned. According to the Fabric chaincode specification, each deployment must be given a version string.
The cleansed app name appended with the version string plus the membership ID (which is also the managed service provider {MSP} ID) forms the label of the chaincode deployment.
For instance, in the above example, the app project is named “Asset-Transfer”, the uploaded chaincode deployment is given the version string “v1”, with the membership ID of the operator being “u0lmaqk8dn”, the label is calculated as “asset_transfer-v1.u0lmaqk8dn”.

Figure 4 – Specify details of the chaincode to deploy.
The chaincode is now ready to deploy into a blockchain environment. Click the Promote to Environment button and select the target environment to deploy to.
Upon promotion, the chaincode is available in the environment but still needs to be installed on the peer nodes, approved, and committed to the desired channels that will use it.
This again can be accomplished by a process triggered from the channel’s initiator organization, and completed without manual intervention from the other member organizations. This is possible thanks to the underlying governance model.
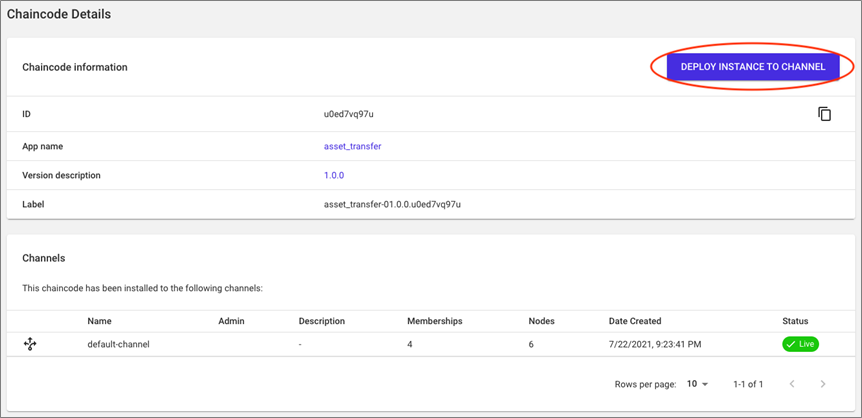
Figure 5 – Deploy the chaincode to the channel after just a few streamlined steps.
In summary, for a channel of any number of member organizations, creation of the channel or deployment of chaincodes can be accomplished in a few streamlined steps. This can be done without having to resort to coordination among the member organizations for digital signatures collection, which tend to get bogged down by the complexity of the communications and procedures in practice.
The Network Operator is able to perform its duty, and the member organizations are able to quickly proceed to the actual business of building the solutions and applications.
REST API for Interacting with Fabric Nodes
Fabric API is based on gRPC, which is an efficient binary wire format. The Fabric transaction model, like almost all blockchain protocols, requires the client to adopt an asynchronous, event-driven programming paradigm.
Powerful client software development kits (SDKs) are available for multiple languages, including golang, node.js, and Java. As with most blockchain protocols, programming with the SDK is a steep learning curve.
Most application developers would rather deal with RESTful APIs using wire formats that are more universally supported than gRPC, such as JSON.
This is where the Fabric Connector comes in. As part of the Hyperledger FireFly project, the firefly-fabconnect component provides a RESTful interface for submitting transactions using JSON payloads. Subscribing to block events or chaincode events that can be delivered in multiple streaming interfaces including websocket connections and webhooks.
With the Fabric Connector, the application developers’ job is made extremely simple. They can accomplish everything involving the Fabric blockchain by using familiar technologies without having to be trained on the Fabric transaction model and learning to use the complex SDKs.
Conclusion
Kaleido supports Hyperledger Fabric by making practical decisions where real-world actors’ experiences are improved without sacrificing the value of the blockchain (data immutability and distributed transaction processing).
Kaleido provides fast time from consortium formation to ready-to-submit-transaction with a fully configured Fabric blockchain. Finally, Kaleido’s full stack approach to the solution development support beyond simple blockchain-as-a-service (BaaS) makes it an ideal platform for building the next generation of collaborative multi-party IT solutions.
To try out Kaleido for yourself, open an account for free. In a couple of minutes, with the free starter plan, you’ll have a fully functional Fabric blockchain network to test with.
Let us know if you have any questions by submitting tickets from inside the console, or send an email to support@kaleido.io.
The content and opinions in this blog are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
.

.
Kaleido – AWS Partner Spotlight
Kaleido in an AWS Partner that provides organizations with a simple and cost-effective platform for launching digital asset solutions and building private blockchain networks.
Contact Kaleido | Partner Overview | AWS Marketplace
*Already worked with Kaleido? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.
Using SailPoint with Amazon EventBridge to Extend Your Governance Platform
=======================
By Sarah Fallah-Adl, Partner Solutions Architect – AWS
By Roy Rodan, Sr. Partner Solutions Architect – AWS
 |
| SailPoint |
 |
In today’s highly complex and dynamic application ecosystem, in addition to a growing virtual workforce, it’s imperative for organizations to have an automated system in place to handle security and compliance.
Event-based notifications enable developers to build rich integrations quicker. This integration, in turn, helps customers connect to various applications without a significant amount of coding or development work.
In this post, we will explore how SailPoint has integrated with Amazon EventBridge to solve various use cases for their customers.
A recognized leader in Identity Governance and Administration (IGA) by Gartner, SailPoint Technologies provides a platform to build custom workflows and integrations to secure access and manage every type of identity.
This platform, SailPoint IdentityNow, is a software-as-a-service (SaaS) solution built on Amazon Web Services (AWS) and available on AWS Marketplace.
“As a strategic partner of AWS, SailPoint is continuously expanding our AWS integrations to ensure that our mutual customers benefit from a best-in-SaaS identity-centric approach to securing the enterprise,” says Eric Yuan, Vice President of Global Strategic Partners at SailPoint.
“With SailPoint’s Amazon EventBridge integration, organizations can now spend less time on technical complexity and more time automating enterprise identity security,” adds Eric.
SailPoint is an AWS Security Competency Partner and Amazon EventBridge integration partner. SailPoint’s identity governance enables enterprises to create a more secure and compliant environment through governed access to AWS.
What is Amazon EventBridge?
Amazon EventBridge is a fully managed service that removes the friction of writing “point-to-point” integrations by letting you easily access changes in data that occur in both AWS and SaaS applications via a scalable, central stream of events.
With EventBridge, you get a simple programming model where event publishers are decoupled from event subscribers. This allows you to build loosely coupled, independently scaled, and highly reusable event-driven applications.
SailPoint Event Triggers is an integration with Amazon EventBridge and SailPoint’s APIs to send event notifications to the customer to provide customization capabilities.
Example integrations include 1) setting up custom notifications in Slack any time a new employee joins your organization, or 2) logging into Amazon CloudWatch every time a new identity is created.
There are currently 28 targets you can choose from, but for the following example we will use Amazon CloudWatch as the destination.
The integrations follow these steps:
SailPoint sends an event to Amazon EventBridge when a new identity is created.
Amazon EventBridge bus receives the event.
Event matches an EventBridge rule.
That matched event is sent to Amazon CloudWatch.
Alternatively, the event could be sent to Amazon Simple Notification Service (SNS) to send a simple text message or email. AWS services such as Amazon Simple Queue Service (SQS), Amazon Kinesis Data Streams, and AWS Lambda can also be leveraged to create custom workflows.
How the SailPoint Integration Works
Let’s walk through the steps of creating a workflow with SailPoint and Amazon EventBridge.
In this example, we’ll set up EventBridge to be triggered when a new identity is created. The destination will be Amazon CloudWatch so you can visualize the results. This is an example of how you can keep track of all incoming events and set the destination accordingly.
To create an implementation, choose the Partner Event Source tab under the Amazon EventBridge service section in your AWS account.
Next, search for SailPoint and select the page to learn how to set up an integration. This is the page the Partner Event Source will populate on once it’s created.

Figure 1 – Searching and setting up SailPoint in Amazon EventBridge.
In the SailPoint user interface (UI), enter the AWS account and AWS region to create the Partner Event source in your account. This will propagate in the AWS account under Partner Event Source in the EventBridge page.
The status of the Partner Event Source goes from pending to active, and the name of the event bus updates to match the partner event source name.
Next, you’ll have to subscribe to a trigger so your integration can take action when the event occurs. SailPoint has a range of trigger events to choose from, and each has a number of potential uses. Please refer to the SailPoint documentation for the current list.
The trigger event for this example would be triggering a response when a new identity is created.
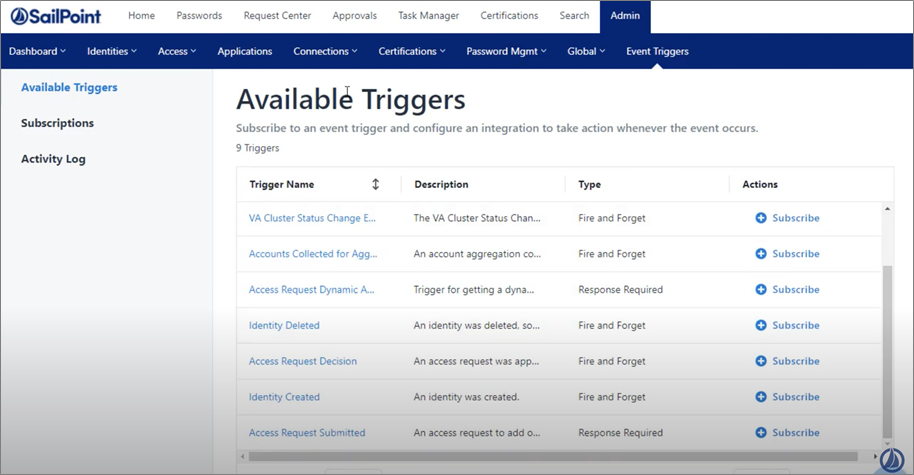
Figure 2 – Select the Identity Created SailPoint triggers.
Now that you’ve configured an event bus, the next step is to attach rules to orchestrate the flow of events. Rules allow matches against values in the metadata and payloads of the events ingested, and determine which events should get routed to which destinations.
When you create a rule:
The rule has to be created in the same region as the target.
Target/destination must be specific in the rule. Targets allow you to invoke a Lambda function, put a record on an Amazon Kinesis Data Stream, and more.
In this example, we’ll set an event trigger to invoke the Amazon CloudWatch rule that was created, and then send the event payload to CloudWatch, which is used to visualize the event’s metadata.
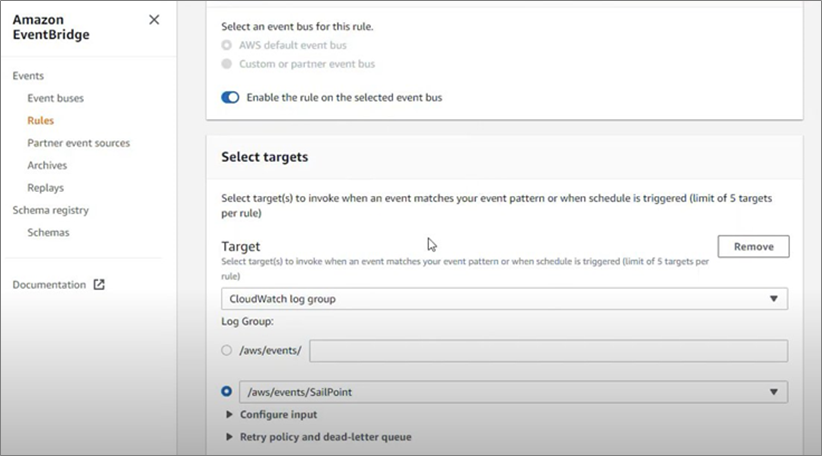
Figure 3 – Selecting targets for an Amazon EventBridge rule.
After you configured Amazon CloudWatch to be the target of the rule, the logs populate once an event triggers the workflow. The log that’s populated as a result of the event can be selected to see the specific metadata for the event.
Combining SailPoint Event Triggers with CloudWatch gives access the performance and operational data of a company. In this example, invocations from creating an identity are available to visualize and use for analytical purposes.
Figure 4 – CloudWatch logs populated from the Amazon EventBridge trigger.
Additional Use Cases
The following are additional use cases for SailPoint Event Triggers. For an up-to-date list of triggers, please to the SailPoint documentation.
Smart notifications: Create a Slack notification for when a new employee starts at your organization or changes role during their employment.
Custom workflows: Automatically reject access into an application where the requestor is deemed to be too risky to obtain access. Automatically kick off a certification campaign for their access if an employee’s manager and department changes.
Quality control: Monitor on a daily basis how many inactive identities you have with active accounts and take immediate action to resolve. Receive an automatic alert as soon as the aggregation process fails so you can address right away.
Access approval options: Customize the approval process by adding the head of security to the approver list for any high sensitive access requests.
Summary
In this post, we showed you the benefits of combining SailPoint identity security with Amazon EventBridge to automate security and compliance.
We shared an example using Amazon CloudWatch to demonstrate how an integration helps a company keep track of critical identity-related events.
For more information about SailPoint, please visit SailPoint AWS integrations page, or check out the recent AWS Howdy Partner episode on Twitch and demonstration that we conducted using SailPoint.
.

.
SailPoint – AWS Partner Spotlight
SailPoint is an AWS Security Competency Partner and Amazon EventBridge integration partner. SailPoint’s identity governance enables enterprises to create a more secure and compliant environment through governed access to AWS.
Contact SailPoint | Partner Overview | AWS Marketplace
*Already worked with SailPoint? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.
How Capgemini is Enabling Organizations and Employees to Return to the Office Using AWS Services
=======================
By Siji Kallarakal, AWS Solution Architect – Capgemini
By Prabhu Padayachi, Data Scientist – Capgemini
By Vivek Dashore, Data Architect – Capgemini
By Sriram Kuravi, Sr. Partner Management Solutions Architect – AWS
 |
| Capgemini |
 |
As the world continues to respond to COVID-19, Capgemini is working to find ways to prepare our communities for such pandemics in the future.
During this extraordinary time, digital solutions have played a crucial role in enabling employees to work remotely. When organizations begin stabilizing normal office operations, there will be a need to create a robust crisis response system. Key areas for businesses to focus on include workforce enablement, crisis management, and operations.
In the pandemic, many organizations are limiting the number of employees within their offices. A business must ensure its employees feel safe within company premises when they return to the office.
To achieve this, an organization must keep a track of employee movement and maintain social distancing policies while allocating workspaces. They should also take quick appropriate action when an infection is reported.
The prototype showcased in this post was built by Capgemini, an AWS Premier Consulting Partner and Managed Service Provider (MSP), and enables an organization to keep track of employee movements within the premises, predict employee sentiment, and help the facilities management team monitor and utilize resources efficiently.
In this post, we share the prototype’s architecture that leverages Amazon Web Services (AWS) machine learning services, Amazon Neptune graph database, and Amazon QuickSight business intelligence, along with native AWS services as building blocks.
Solution Overview
Parts of Capgemini’s prototype can be extended to organizations dealing with high footfalls such as recreation areas, movie theatres, and shopping malls.
Key benefits of the solution include:
Optimal utilization of workplace, parking and lifts: A dashboard showing utilization of work facilities is available to the central admin team to help them detect crowding. In lifts, the solution leverages Radio Frequency ID (RFID) on employee swipe cards for tracking and to and detect crowding.
Contact tracing: Identifies probable infections based on proximity data collected from RFID devices at various locations in the organization.
Employee health and sentiment monitoring: Knowing people’s health status is paramount in pandemic times and can be declared on the company’s self-service app. The app also captures employee feedback and uses machine learning (ML) services to analyze sentiment.
Common area crowding: In common areas like cafeterias, proximity detection and alerting users from the company’s self-service app using COVID Watch technology, to ensure employee safety.
Building the Prototype
The diagram below depicts the employee journey at work, and explores the data capture opportunities.
In an emergency, where companies need to build and deploy a solution within a brief period, cloud-based services from AWS helped Capgemini come up with a solution which would typically take months to build and launch.

Figure 1 – Employee journey.
Capgemini’s solution is driven by analyzing the data captured at multiple points:
Start: The employee enters their health data into the company’s self-service app, which is fed to the solution.
Reception entry: Once an employee reaches office and swipes their ID card, temperature details are captured in the system. If it’s over the threshold, an alert will be sent to the admin team as email and SMS.
Lift lobby: When an employee enters the lift, employee RFID detail is captured and later coupled with lift usage details.
Cubicle seating: Floor-plan data such as cubicle layout available in the facilities management application is leveraged for calculating capacity based on proximity calculations.
Cafeteria access: When an employee enters or exists the cafeteria, the RFID detail is captured. The solution calculates time spent at the cafeteria and number of employees present in cafeteria at any instance of time.
COVID Watch technology: Integration of an organization’s self-service app with COVID Watch technology (open source framework) enables the gathering of interaction details (time and distance) with other employees.
Feedback survey: Employee satisfaction ratings are captured in a survey form. This is used to predict sentiment of employees who may not have filled out forms, or for those who are yet to start working from company premises, based on similar traits.
Architecture
Layers are outlined in Figure 2 to explain the data flow. Data sources include real-time data like temperature readings, and batch data related to employees and facilities, as well as employee swipe records at each gate, door, or lift.
These are captured in the data layer using appropriate storage services for streams, data lakes, and graph databases. In the business layer, cloud functions process business logic, while for the web frontend it uses API gateway. The presentation layer encompasses visualization coupled with graphs.

Figure 2 – Data flow through the layers.
The illustration below gives a technical architecture view of the AWS services used to materialize the prototype. The client accesses the application via web site hosted on Amazon Simple Storage Service (Amazon S3), and actions exposed on Amazon API Gateway.
The connections are through secure virtual private network (VPN) tunnel to transmit data securely to AWS.
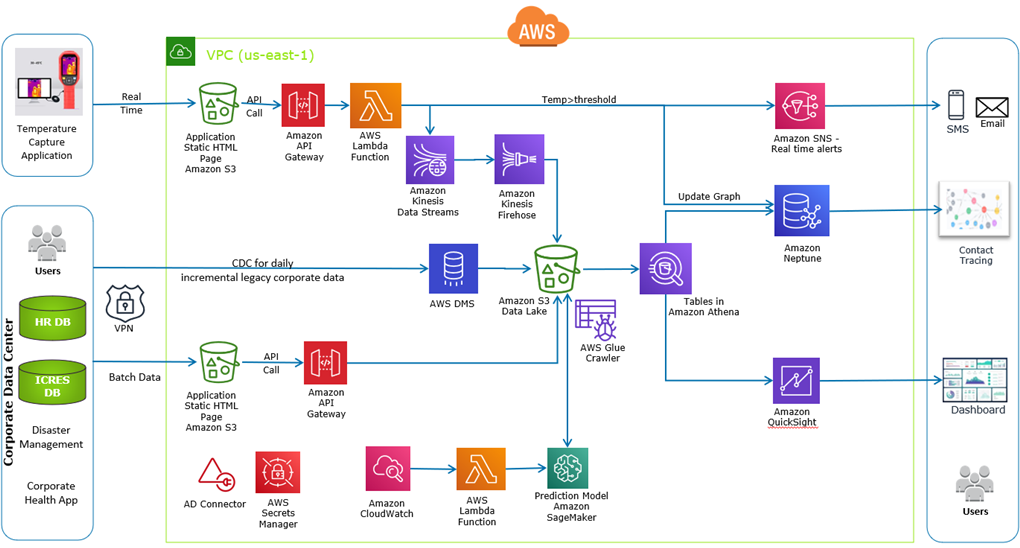
Figure 3 – Technical architecture diagram.
Building Blocks
#1 – Closely tracking employee interaction to isolate them in case of infection
Employee movements on company premises are captured by RFID devices when they swipe their ID cards. This information is ingested into Amazon S3, which is then fed to Amazon Neptune in batches to generate relationships between individuals who have been in proximity or interacted.
Employee contact tracing is computed based on the presumption that employees who swipe to enter the facility (office, cafeteria, lift) around the same time have been in proximity. This data is used to create relationships in the Amazon Neptune graph database, which is used to create the contact tracing when a suspected infection is detected.
Amazon S3 acts as the data lake for all ingested data files. The file metadata is created in AWS Glue Data Catalog by the AWS Glue crawlers that scan the files ingested in S3. Using Amazon Athena, the data files in Amazon S3 data lake are exposed as structured tables for consumption by downstream applications such as Amazon Neptune and Amazon QuickSight for further reporting and decision making.
When an employee swipes their ID card upon entering the office premises, their temperature is captured using a digital thermometer device and sent to AWS via a static web application hosted on Amazon S3. This triggers an API call in Amazon API Gateway that sends the employee ID and temperature data to an AWS Lambda function.
If the temperature is detected above a defined threshold value of 100°F, the AWS Lambda function invokes Amazon Simple Notification Service (SNS) alert and sends SMS/email to the admin team in real-time about an employee with fever.
In parallel, the AWS Lambda function also inserts this record in Amazon Kinesis Data Streams. This data record is picked up by an Amazon Kinesis Data Firehose delivery stream and sent to Amazon S3 in batches every five minutes. The function also updates a symptomatic flag in the Amazon Neptune graph relationship to enable the office admin team to quickly establish contact tracing.
The following sample code represents how the event is handled by AWS Lambda, which sends SMS and email alerts in real time when an individual with high temperature is detected:
code = json.dumps(event['insert'])
json_data=json.loads(code)
json_data['timestamp'] = datetime.datetime.fromtimestamp(time.time()).strftime('%Y-%m-%d %H:%M:%S')
employee = json_data["Empid"]
temperature = json_data["Temp"]
message = "Employee : "+ str(json_data["Empid"])+ " has temperature : " + str(json_data["Temp"])
#Setting Threshold temperature as 100 degrees F
#Send Email and SMS when the threshold is crossed.
if(temperature>=100):
response_sms = sns_client.publish(TargetArn = "arn:aws:sns:us-east-1: 123456789012:High_Temp_Alert",Message = message )
response_email = sns_client.publish(TargetArn = "arn:aws:sns:us-east-1: 123456789012:Api_temp",Message = message )
#2 – Predicting employees’ readiness to return to office
To check the feasibility of employees’ willingness to come to the office for smooth operations, it’s important to conduct a survey. We can’t expect all employees to respond, however.
In such a scenario, businesses need to predict the survey responses for the employees who have not responded. Once the prototype’s machine learning model is trained and tuned, Amazon SageMaker makes it easy to deploy in production and generate predictions on new data.
AWS Database Migration Service (AWS DMS) is used to batch loads of employee details to Amazon S3 from on premises. This data consists of master data for employee and facilities swipe data records (cubicle, floor, cafeteria).
Where possible, change data capture (CDC) is used at the source to enable incremental data loads. AWS DMS was chosen over an extract, transform, load (ETL) tool, as it provides functionality of data migration along with CDC at a much lower cost.
The latest information about facility utilization (cubicle, transport, capacity) is posted by the admin team from a static web application hosted on Amazon S3. This data is also written to S3.
Employee survey data captured as a part of employee feedback is also ingested in S3. This critical data is used for creating a trained ML model using Amazon SageMaker for predicting the happiness score of employees.
Amazon CloudWatch is scheduled to trigger an AWS Lambda function daily to call the Amazon SageMaker endpoint. The predictions are then written back to Amazon S3.
The following sample code represents logic for sentiment analysis and infection prediction:
ALGORITHM_OBJECTIVE_METRICS = {
'xgboost': 'validation:f1',
'linear-learner': 'validation:macro_f_beta',
}
STATIC_HYPERPARAMETERS = {
'xgboost': {
'objective': 'multi:softprob',
'num_class': 3,
},
'linear-learner': {
'predictor_type': 'multiclass_classifier',
'loss': 'auto',
'mini_batch_size': 800,
'num_classes': 3,
},
}
from pprint import pprint
from sagemaker.analytics import HyperparameterTuningJobAnalytics
SAGEMAKER_SESSION = AUTOML_LOCAL_RUN_CONFIG.sagemaker_session
SAGEMAKER_ROLE = AUTOML_LOCAL_RUN_CONFIG.role
tuner_analytics = HyperparameterTuningJobAnalytics(
tuner.latest_tuning_job.name, sagemaker_session=SAGEMAKER_SESSION)
df_tuning_job_analytics = tuner_analytics.dataframe()
# Sort the tuning job analytics by the final metrics value
df_tuning_job_analytics.sort_values(
by=['FinalObjectiveValue'],
inplace=True,
ascending=False if tuner.objective_type == "Maximize" else True)
# Show detailed analytics for the top 20 models
df_tuning_job_analytics.head(20)
from sagemaker.tuner import HyperparameterTuner
base_tuning_job_name = "{}-tuning".format(AUTOML_LOCAL_RUN_CONFIG.local_automl_job_name)
tuner = HyperparameterTuner.create(
base_tuning_job_name=base_tuning_job_name,
strategy='Bayesian',
objective_type='Maximize',
max_parallel_jobs=2,
max_jobs=250,
**multi_algo_tuning_parameters,
)
Finally, deploy the model to Amazon SageMaker to make it functional:
pipeline_model.deploy(initial_instance_count=1,
instance_type='ml.m5.2xlarge',
endpoint_name=pipeline_model.name,
wait=True)
#3 – Optimizing facility utilization while maintaining social distancing
Due to social distancing norms within an organization’s premises, there’s a need to detect and minimize crowding in employee interaction zones such as workspaces, cafeterias, and lifts.
This can be achieved by analyzing the data collected by various applications like swipe records and floor capacity. Capgemini’s prototype has several dashboards built with Amazon QuickSight for providing insights on space utilization and capacity management, helping the office admin to take quick decisions in maintaining social distancing norms.
To enable the admin team to see the complete picture through a single pane, the prototype encompasses analytics dashboards in Amazon QuickSight, which is scalable and provides a serverless business intelligence service on the cloud compared to traditional BI tools.
Amazon QuickSight enables users to access dashboards from any device, and can be seamlessly embedded into applications, portals, and websites.
The Capgemini prototype contains these reports:
Utilization of resources such as lifts and workspaces: The visual below gives a peek on lift utilization in peak hours, and based on traffic and waiting time. With respect to workspace utilization, this is to aid office admins in allocating cubicles to avoid crowding hotspots.
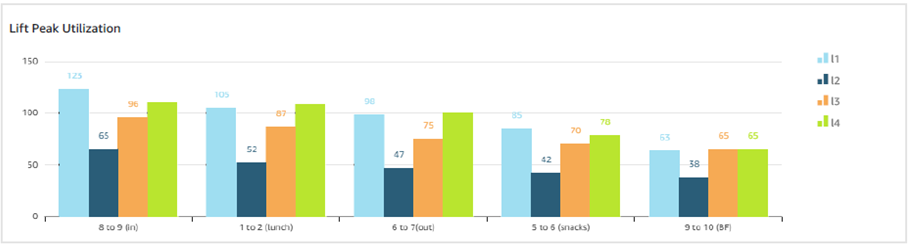
Figure 4 – Lift utilization.
Canteen utilization: This chart shows the canteen utilization compared to the capacity at different time ranges (breakfast, lunch, dinner). If the utilization rate is low, the capacity plan can be altered. If the utilization is at peak capacity, management needs to consider increasing capacity, or schedule time slots for employee groups.
.
Infection prediction: This chart shows employee-wide status of infected, quarantined, and safe.
.
Zone-wise employee: This visual gives easy access to management about employee count per block in the office premises. If employee count is higher for a zone, a decision can be made to change seat arrangement, for example.

Figure 5 – Zone-wise employee distribution.
Contact tracing: The graph below helps the admin team quickly identify employees who have been in close proximity to the infected employee, and act instantly.
Figure 6 – Contact tracing using graphs.
The above visual represents the interactions between different individuals, wherein red nodes represent an infected person, and blue ones are uninfected. This contact tracing representation helps the admin to identify quickly and alert individuals who have interacted with infected person.
Ensuring Security
The Capgemini prototype implements the following features out of the box:
All data resides in Amazon S3 and is encrypted at rest using SSE-S3.
Integration with on-premises Active Directory for authorized access.
Designed on industry standards compliant AWS services.
Hosted within secure Amazon Virtual Private Cloud (VPC).
Connection to AWS VPC through secure VPN tunnel.
Services assume AWS Identity and Access Management (IAM) roles ensuring least privilege policies, to provide Role Based Access Control (RBAC).
AWS Secrets Manager is leveraged to store Keys.
Designing for Reliability
The prototype was designed with AWS-native managed services providing high availability, durability, and reliability:
Leverages serverless AWS technologies such as Amazon Athena, AWS Lambda, Amazon Neptune, and Amazon QuickSight.
All data, both real-time and batch, are stored in Amazon S3, which provides 99.999999999% durability. This data was exposed as Amazon Athena tables based on AWS Glue Data Catalog.
Temperature data streams storage on Amazon Kinesis for real-time service that’s scalable and durable.
Using Amazon SageMaker, the machine learning model can be deployed on an auto-scaling cluster of Amazon Elastic Compute Cloud (Amazon EC2) instances that are spread across multiple AWS Availability Zones to deliver high performance and high availability.
Summary
The pandemic has been challenging for organizations in so many ways. The need to provide a safe and productive environment for employees when they return to work on premises has become even more important.
The Capgemini prototype outlined in this post enables organizations to quickly onboard employees while following necessary pandemic protocols. Moreover, it enables businesses to track and take correction active immediately.
We have shown how organizations can build a solution quickly that enables it to be fully functional, while also prioritizing employee safety.
.

.
Capgemini – AWS Partner Spotlight
Capgemini is an AWS Premier Consulting Partner and MSP. With a multicultural team of 220,000 people in 40+ countries, Capgemini has more than 12,000 AWS accreditations and over 2,700 active AWS Certifications.
Contact Capgemini | Partner Overview
*Already worked with Capgemini? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.
Increase Operational Efficiency and Drive Faster Business Outcomes with UiPath Robots on AWS
=======================
By Meenakshisundaram Thandavarayan, Sr. Partner Solution Architect – AWS
By Seenu Brahmarouthu, Sr. Partner Development Manager – AWS
By Jessica Ng, Sr. Product Partnership Lead – UiPath
 |
| UiPath |
 |
Organizations are pursuing agility by developing automation for business processes using virtual robots.
Robotic process automation (RPA) makes it easy to build, deploy, and manage software robots that emulate humans’ actions interacting with digital systems and software. RPA adoption lies at the center of many digital transformation efforts.
To be effective, RPA technology must support you end-to-end, from discovering automation opportunities to quickly building high-performing robots, and from managing thousands of automated workflows to measuring the impact of your automations.
Enterprises need technology that can go far beyond simply helping you automate a single process. According to Gartner, “Robotic process automation remains the fastest-growing software market, as RPA is one of the popular choices for improving operational efficiency.”
UiPath offers an end-to-end platform for automation with the enterprise-ready cloud infrastructure, artificial intelligence (AI) services, and intelligent automation solutions from Amazon Web Services (AWS) that provide the foundation to scale your enterprise automation.
This can help you accelerate deployment, integrate with AWS AI and machine learning (ML) services, and leverage built-in intelligent automation solutions such as customer experience in the contact center and document processing.
UiPath is an AWS Partner and leader in the “automation first” era that is enabling robots to learn new skills through artificial intelligence and machine learning.
UiPath platform on AWS provides the following capabilities:
Increased speed and agility: Quickly deploy the UiPath platform on AWS using deployment accelerators:
AWS Quick Start for UiPath
AWS Marketplace
Automation Suite
Stop guessing capacity: Eliminate the need to pre-warm your virtual machines (Amazon EC2) that are running robots, and allow UiPath to scale and manage your robots on AWS with Elastic Robot Orchestration.
Get automating faster: Leverage pre-built UiPath and AWS intelligent automation solutions, including AWS IT automation activities and contact center automation.
Boost intelligence in your automations: Seamless integration of UiPath RPA with AWS AI/ML services. UiPath’s integration with AWS AI devices opens up new use cases to bring AI into the business process by leveraging UiPath’s cognitive RPA capabilities.
RPA Primer
Before exploring how to leverage AWS and UiPath for digital automation, let’s quickly review the key components of any RPA solution.
Figure 1 – Key components of RPA.
The RPA Development phase represents the design of a process that needs to be automated. UiPath Studio is a design tool with drag-and-drop capability to design the process workflow.
Alternatively, processes can be designed using a recorder and customized in UiPath Studio. The output of RPA development is a process script.
The RPA Runtime phase represents the virtual robots that execute the process that’s designed using UiPath Studio. UiPath delivers these robots as attended and unattended.
Attended robots run under human supervision and, because of this, are best suited for use with smaller, more fragmented tasks that work closely alongside humans. Unattended robots are intended for more complex and highly repetitive tasks that don’t require human intervention. This usually needs to be performed in batches that can be decided using a predefined rule.
Based on the process and use case, UiPath can facilitate a seamless handoff between the attended and unattended robots.
The RPA Management phase enables you to manage the designed processes and schedule them to run on virtual robots. UiPath Orchestrator enables you to orchestrate your UiPath Robots in executing business processes. Orchestrator also lets you manage the creation, monitoring, and deployment of resources in your environment.
In addition to those core components, UiPath provides an end-to-end automation platform that starts with process discovery and task mining capabilities to discover what to automate.
The platform provides citizen and professional development capabilities to build, manage, and run robots, and human-in-the-loop capabilities to engage and govern human users. There are also analytics to measure the return on investment (ROI) from the automations.
Now, let’s now look at how AWS and UiPath can help accelerate your journey towards digital automation.
Deploying UiPath on AWS
AWS and UiPath provide you with flexibility in deploying the platform. From small automation projects to company-wide extensive scopes, the UiPath platform can scale on AWS to meet any enterprise need, from front to back office.
UiPath’s prebuilt auto-deployment templates on AWS ensure fast deployment and quick ROI for time and cost savings.
You can deploy the UiPath automation platform on your Amazon Virtual Private Cloud (VPC) or leverage the UiPath Automation Cloud with Elastic Robot Orchestration to reduce your overhead on maintenance.
You can choose to install the core components of the RPA platform—UiPath Orchestrator and UiPath Robots—on your VPC using the AWS Quick Start for UiPath.
AWS Quick Starts are ready-to-use accelerators that fast-track deployments of key cloud workloads for customers. These accelerators reduce hundreds of manual procedures into automated, workflow-based reference deployments for AWS Partner technologies, built according to AWS best practices.
Figure 2 – AWS Quick Start for UiPath.
You can choose to deploy the UiPath end-to-end automation platform via UiPath Automation Suite. This enables you to install the complete UiPath suite of products and capabilities on AWS as a single, containerized suite with scaling, high availability, and backup capabilities in your VPC.
UiPath Automation Suite helps you manage all of your automation work and resources in one place. You can keep track of licenses, add multiple tenants with different services, manage user access across services, create/connect to UiPath Robots, run jobs and processes, and create schedules-all from one centralized location of your choice.
Please refer to the UiPath documentation that details out how to deploy Automation Suite on your VPC.
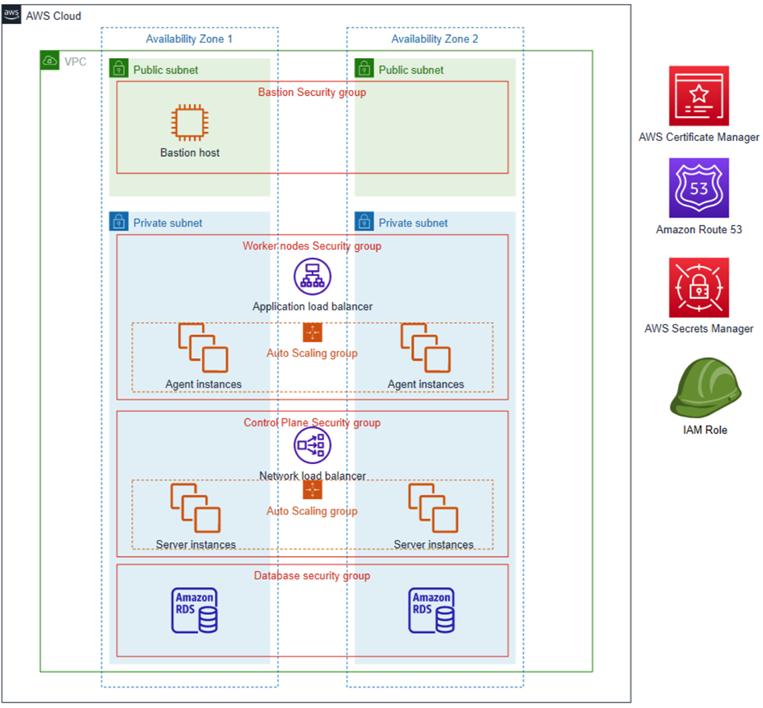
Figure 3 – UiPath Automation Suite on AWS.
You can also leverage UiPath’s Elastic Robot Orchestration capability that is enabled with the UiPath Automation Cloud.
With Elastic Robot Orchestration, you can dynamically provision, scale, and optimize unattended robots from UiPath Automation Cloud to your VPC. This helps lower your cost of operations and reduce the overhead of managing, patching, and upgrading the UiPath Orchestrator and Robots.
Figure 4 – Elastic Robot Orchestration and UiPath Automation Cloud.
To leverage UiPath Automation Cloud with Elastic Robot Orchestration, create a generalized Amazon Machine Image (AMI) you want to use as a template for robots. Next, log in to UiPath Automation Cloud and set up your tenant.
Connect your tenant to your AWS account / VPC where you wish to run the robots, and then register the AMI as a cloud machine pool in your tenant.
UiPath Automation Cloud can elastically orchestrate the creation of virtual machines in your VPC, install the robot runtime, and execute the process. Once completed, it shuts down the virtual machines. For step-by-step instructions, refer to UiPath documentation.
Leveraging AWS AI/ML to Drive Cognitive Automation
Once the UiPath platform is deployed on AWS, you can start building your processes using UiPath Activities—the building blocks to create the automation process—in UiPath Studio.
Activities form into comprehensive workflows in UiPath Studio, which are then executed by Robots and published to Orchestrator.
UiPath Robots are great at emulating repetitive rules-based activities more quickly, accurately, and tirelessly, but they require humans for reasoning and judgement. When UiPath Robots can reason over data and use AWS AI to make decisions, your business can unlock new transformation possibilities.
UiPath and AWS have created Activities that natively integrate UiPath RPA with AWS AI/ML services to bring artificial intelligence capabilities directly into the business process.
Next, we’ll address a real-life use case of extracting valuable information. Unstructured data volume within organizations are increasing quickly, and companies are rapidly falling behind in leveraging it.
Business units like finance and human resources, as well as document-intensive industries such as insurance, banking, manufacturing, healthcare, and the public sector, spend countless hours reading documents, pulling information from them, and making sure the correct action is taken based on that information.
Below is a reference architecture of UiPath leveraging AWS AI services to address the intelligent document processing. For the purpose of simplicity, you can categorize the architecture in to two broad components.
UiPath end to end automation platform:
UiPath Orchestrator with high availability add-ons.
Amazon Relational Database Service (Amazon RDS) for process repository.
UiPath Robots running on Amazon Elastic Compute Cloud (Amazon EC2) instances.
AWS AI services for natural language processing (NLP):
Amazon Textract for document processing.
Amazon Comprehend for document classification.
Amazon Translate for language translation.
Amazon Rekognition for detecting text from images in the document.
Amazon SageMaker for custom NLP models.
Figure 5 – UiPath on AWS reference architecture.
UiPath powered by Amazon Textract, Amazon Comprehend, and other AI services, can read, extract, interpret, classify, and act upon data from the documents with a high level of accuracy and reliability.
This enables automation of various document-intensive business chores which usually require highly-manual processing. The includes invoice processing, insurance claims, new-patient onboarding, proof of delivery, and order forms.
Figure 6 – UiPath and Amazon Textract integration.
A connectivity to your AWS account from UiPath Studio needs to be established before using the AWS AI/ML services.
Amazon Scope is another UiPath Studio extension that helps you establish an authenticated connection to your AWS account. It uses an AWS Identity and Access Management (IAM) user-based authentication, creates an IAM user within your AWS account, and assigns the required policies and permissions that specify the AWS resources your robots can access based on your use case.
You can use Amazon Textract and Amazon Comprehend for addressing NLP and document-based requirements, and Amazon Rekognition for image and video processing.
Once Amazon Scope establishes the connectivity between UiPath and your AWS account, you can call the required AWS AI/ML services endpoint within your process design. Using Amazon Scope, you can write code to integrate with custom built models developed and hosted as endpoints in Amazon SageMaker.
With this integration, the possibilities of bringing in cognitive capabilities on to your UiPath Studio process design are endless.
Automate Faster with Intelligent Automation Solutions
Customers are able to leverage joint use case solutions from UiPath and AWS with prebuilt integrations for accelerating automations in the IT department and in the contact center.
Prebuilt solutions can be leveraged in customer service and contact center automation as well, with Amazon Connect and Amazon Contact Center Intelligence (CCI).
UiPath has a bi-directional integration with Amazon Connect, with an Activity Pack to automate an outbound call via Amazon Connect as part of a workflow. It also has a Connector from the Amazon Connect IVR and Chat capability that directly triggers a UiPath Robot to run a process based on the customer conversation.
For customers leveraging CCI in their contact center, critical AI services such as Amazon Comprehend can be used to detect customer sentiment as part of the prebuilt Activity Packs.
Conclusion
Using UiPath on AWS, robotic process automation (RPA) administrators and RPA developers can deliver and scale a true enterprise-grade end-to-end automation platform.
The results of automation drive business outcomes and KPIs for line of business leaders and executives alike, delivering operational savings and efficiencies, improving customer experience, minimizing risk and ensuring compliance in operations, and increasing employee engagement.
Automating document processing is a great example of this, but the use cases are limitless in all types of industries, from the front to back office.
To get started with UiPath on AWS, use AWS Quick Starts or AWS Marketplace.
.

.
UiPath – AWS Partner Spotlight
UiPath is an AWS Partner and leader in the “automation first” era enabling robots to learn new skills through AI/ML.
Contact UiPath | Partner Overview | AWS Marketplace
*Already worked with UiPath? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.
IBM Cloud Pak for Data Simplifies and Automates How You Turn Data into Insights
=======================
By Mark Brown, Sr. Partner Solutions Architect – AWS
By Linh Lam, Sr. Partner Solution Architect – AWS
 |
| IBM |
 |
Many data-driven workloads will take advantage of artificial intelligence (AI), but businesses still face challenges in delivering real AI solutions operationally. Data is often locked up in silos or is not business-ready in other important ways.
Customers also face strains in their on-premises data infrastructure due to aging, high maintenance, resource and energy costs, and expansion requirements. Many have chosen Amazon Web Services (AWS) for its wide range of cost-effective data storage services and industry-leading technical resources.
AWS and IBM recently announced that IBM Cloud Pak for Data, a unified platform for data and AI, has been made available on AWS Marketplace. You can easily test, subscribe to, and deploy the Cloud Pak for Data platform on AWS.
By running on Red Hat OpenShift and being integrated with AWS services, the platform simplifies data access, automates data discovery and curation, and safeguards sensitive information by automating policy enforcement for all users in your organization.
IBM Cloud Pak for Data comes with well-known applications in categories such as:
Built-in data governance applications (IBM Watson Knowledge)
Data quality and integration applications (IBM DataStage)
Model automation (IBM Watson Studio)
Purpose-built AI model risk management
By offering a unified suite of data management and governance, AI, and machine learning (ML) products, the platform delivers on the following use cases:
Data access and availability: Eliminate data silos and simplify your data landscape to enable faster, cost-effective extraction of value from your data.
Data quality and governance: Apply governance solutions and methodologies to deliver trusted business data.
Data privacy and security: Fully understand and manage sensitive data with a pervasive privacy framework.
ModelOps: Automate the AI lifecycle and synchronize application and model pipelines to scale AI deployments.
AI governance: Ensure your AI is transparent, compliant, and trustworthy with greater visibility into model development.
Unlocking the Value of Your Data
Built on Red Hat’s OpenShift Container Platform, IBM Cloud Pak for Data gives you access to market-leading IBM Watson AI technology on AWS’ highly available, on-demand infrastructure. In addition, auto scaling capabilities enable you to rapidly establish a single data and AI platform at global scale.
Customers gain a streamlined data pipeline, leveraging the AWS services they are using to collect data and feed it directly into IBM Cloud Pak for Data to generate actionable insights in real time. This gives you the ability to create a federated data model and extend data and business services to pull data from multiple sources
Prerequisites
This product requires a moderate level of familiarity with AWS services. If you’re new to AWS, visit the Getting Started with AWS and AWS Training and Certification pages. These sites provide materials for learning how to design, deploy, and operate your infrastructure and applications on the AWS Cloud.
This product also assumes basic familiarity with IBM Cloud Pak for Data components and services. If you’re new to IBM Cloud Pak for Data and Red Hat OpenShift, please see these additional resources.
It’s highly recommended the IBM Cloud Pak for Data Deployment Guide be consulted and reviewed prior to using this product.
Using AutoAI in Cloud Pak for Data
In this post, we will introduce you to AutoAI as an example to demonstrate one of Cloud Pak for Data’s capability to simplify the model automation process.
AutoAI is a graphical tool in Watson Studio that automatically analyzes your data and generates candidate model pipelines customized for your predictive modeling problem.
IBM Cloud Pak for Data comes ready to connect to your AWS data sources:
Amazon RDS for MySQL
Amazon RDS for Oracle
Amazon RDS for PostgreSQL
Amazon Redshift
Amazon S3
Amazon Athena
For example, if your data is in Amazon Simple Storage Service (Amazon S3), you can connect S3 to IBM Cloud Pak for Data at a platform level, making your S3 files accessible for use by Watson services.
The easy-to-use instructions on how to make the connection are found in the IBM documentation.
To create the connection asset, you need these connection details:
Bucket name that contains the files.
Endpoint URL: Include the region code. For example, https://s3.<region-code>.amazonaws.com. For the list of region codes, see AWS service endpoints.
Region: This is the AWS region. If you specify an endpoint URL that is not for the AWS default region, then you should also enter a value for Region.
Credentials:
Access key
Secret key
Let’s start by picking the data source; in this case, we’re using a market data set and would like to predict mortgage default risk. The following screenshot demonstrates the AutoAI configuration in a graphic interface.
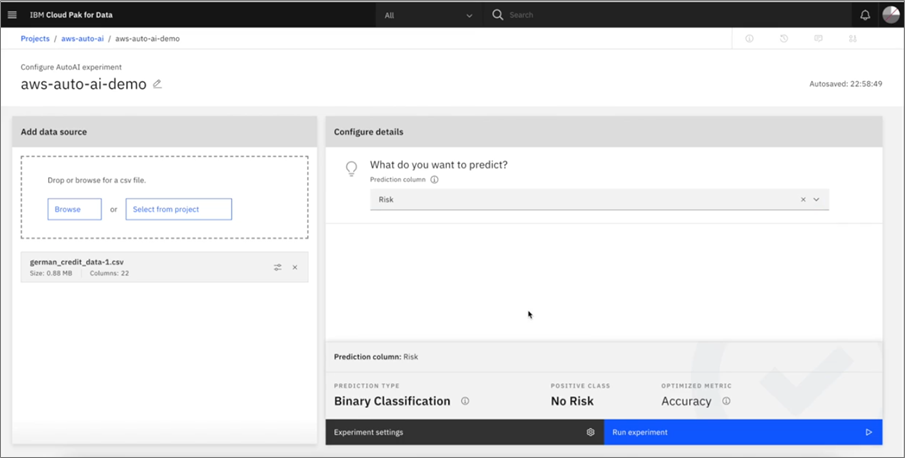
Figure 1 – Configuring an AutoAI experiment.
Once it parses the data file, it will give the option to pick one or more features or attributes of that data set for use during production. The experiment is an automation that enables us to go through the data sets, build out features, and automatically apply transformation to the data.
The next screenshot shows the tool in the process of going through candidate algorithms to build “pipelines” for the data processing that will produce models.
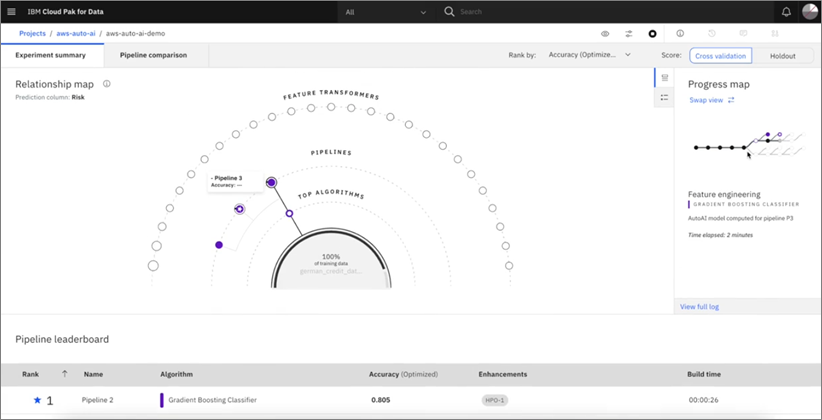
Figure 2 – Map of algorithmic paths.
While this process can take some time depending on the amount and complexity of the data sets, the end result is a set of eight pipelines ordered by accuracy.
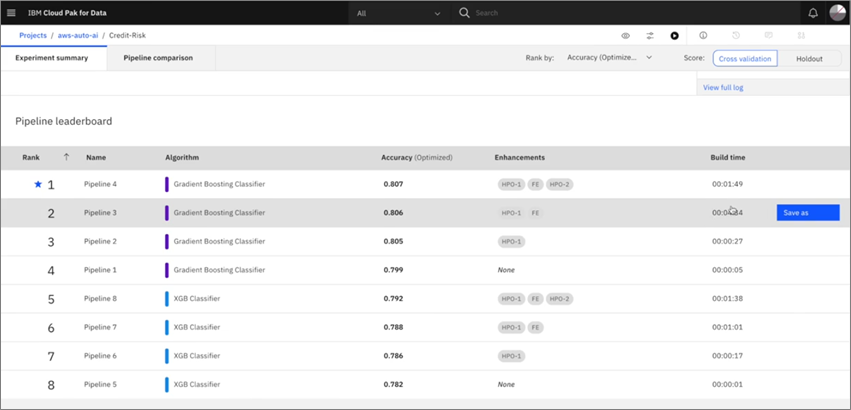
Figure 3 – Pipeline selection.
These are models you can save, deploy, and expose as endpoints. Once the endpoint has been created, users can look at examples of how to consume that model’s invoked predictions in various different program languages.
Here’s an example Scala code snippet for use with the model just created.
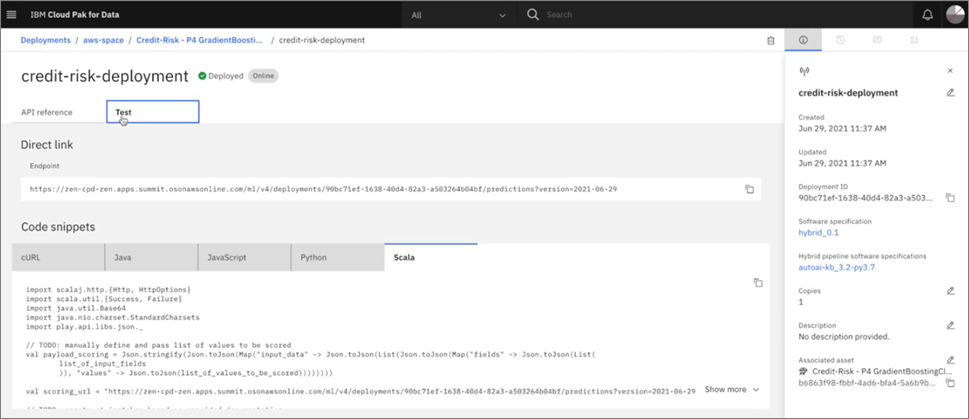
Figure 4 – Sample code in popular languages.
Conclusion
IBM and AWS have provided a unified way to acquire and deploy IBM Cloud Pak for Data using Red Hat OpenShift. This solution enables your organization to simplify and automate how it collects, organizes, and analyzes data using AI and machine learning technologies.
Additionally, IBM Cloud Pak for Data users can use this same mechanism to purchase and deploy the optional additional software, known as cartridges, to their IBM Cloud Pak installation using the same selection and billing model.
Customers can spend more time using their system and less time managing multiple payment and licensing environments.
To get started, download IBM Cloud Pak for Data on AWS Marketplace.
.

.
IBM – AWS Partner Spotlight
IBM is an AWS Partner that provides advanced cloud technologies and the deep industry expertise of IBM services and solutions professionals and consultants.
Contact IBM | Partner Overview | AWS Marketplace
*Already worked with IBM? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.
Page 1|Page 2|Page 3|Page 4